tidb-in-action
第2章 说存储
在前一节中,我们介绍了 TiDB 项目的几个主要的组成部分,本节向大家介绍一下 TiKV 的一些设计思想和关键概念。
2.1 Key-Value Pairs (键值对)
作为保存数据的系统,首先要决定的是数据的存储模型,也就是数据以什么样的形式保存下来。TiKV 的选择是 Key-Value 模型,并且提供有序遍历方法。 TiKV 数据存储的两个关键点:
- 这是一个巨大的 Map(可以类比一下 C++ 的 std::map),也就是存储的是 Key-Value Pairs(键值对)
- 这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是可以 Seek 到某一个 Key 的位置,然后不断地调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value。
有人可能会问,这里讲的存储模型和 SQL 中表是什么关系?在这里有一件重要的事情需要强调:
TiKV 的 KV 存储模型和 SQL 中的 Table 无关!
现在让我们忘记 SQL 中的任何概念,专注于讨论如何实现 TiKV 这样一个高性能、高可靠性、分布式的 Key-Value 存储。
2.2 本地存储(RocksDB)
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
2.3 Raft 协议
接下来 TiKV 的实现面临一件更难的事情:如何保证单机失效的情况下,数据不丢失,不出错?
简单来说,需要想办法把数据复制到多台机器上,这样一台机器挂了,其他的机器上的副本还能提供服务; 复杂来说,还需要这个数据复制方案是可靠和高效的,并且能处理副本失效的情况。TiKV 选择了 Raft 算法。Raft 是一个一致性协议,它和 Multi Paxos 实现一样的功能,但是更加易于理解。这里 是 Raft 的论文,感兴趣的可以看一下。本书只会对 Raft 做一个简要的介绍,细节问题可以参考论文。 Raft 提供几个重要的功能:
- Leader(主副本)选举
- 成员变更(如添加副本、删除副本、转移 Leader 等操作)
- 日志复制
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。不过在实际写入中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
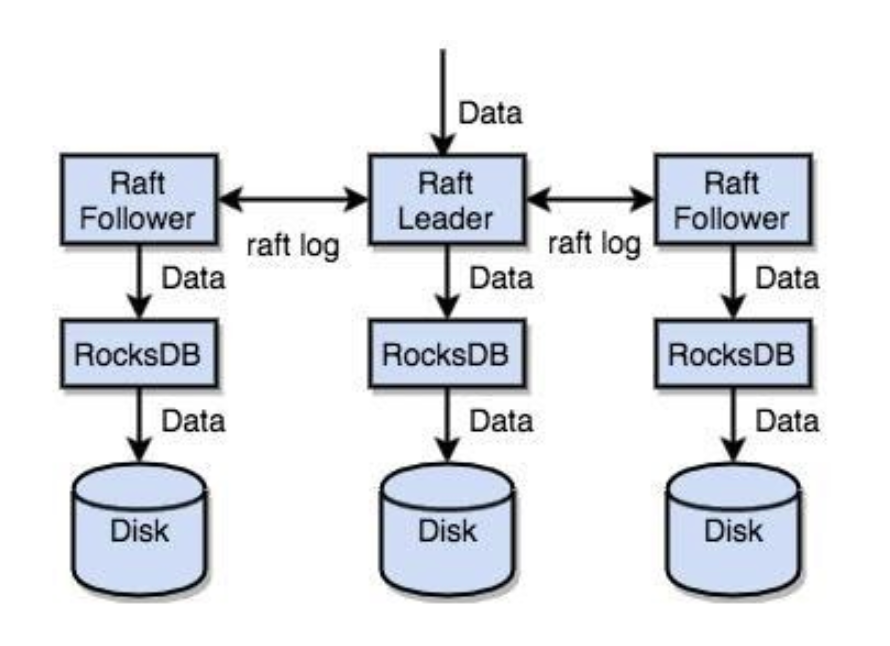
总结一下,通过单机的 RocksDB,TiKV 可以将数据快速地存储在磁盘上;通过 Raft,将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,TiKV 变成了一个分布式的 Key-Value 存储,少数几台机器宕机也能通过原生的 Raft 协议自动把副本补全,可以做到对业务无感知。
2.4 Region
讲到这里,我们需要提到一个非常重要的概念:Region。这个概念是理解后续一系列机制的基础,请仔细阅读这一小节。 前面提到,我们将 TiKV 看做一个巨大的有序的 KV Map,那么为了实现存储的水平扩展,我们需要将数据分散在多台机器上。这里提到的数据分散在多台机器上和 Raft 的数据复制不是一个概念,在这一节我们先忘记 Raft,假设所有的数据都只有一个副本,这样更容易理解。 对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:
- Hash:按照 Key 做 Hash,根据 Hash 值选择对应的存储节点
- Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上
TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey,EndKey) 这样一个左闭右开区间来描述。
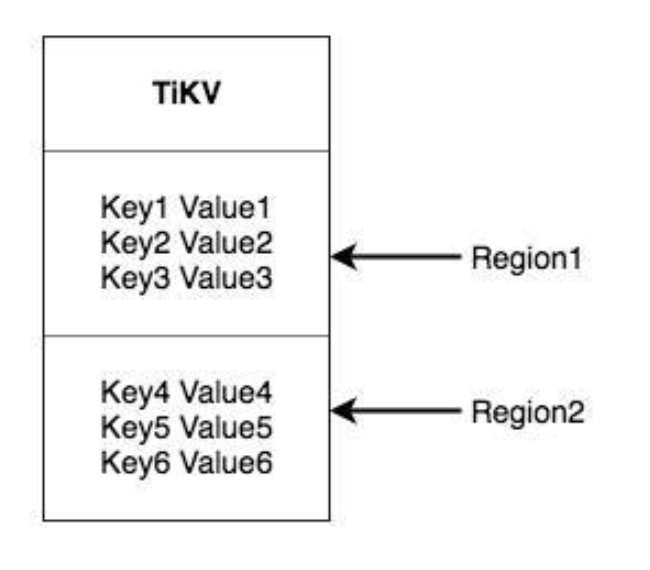
注意,这里的 Region 还是和 SQL 中的表没什么关系! 请各位继续忘记 SQL,只谈 KV。 将数据划分成 Region 后,TiKV 将会做两件重要的事情:
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
- 以 Region 为单位做 Raft 的复制和成员管理
这两点非常重要,我们一点一点来说。 先看第一点,数据按照 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面(暂不考虑多副本)。TiDB 系统会有一个组件(PD)来负责将 Region 尽可能均匀的散布在集群中所有的节点上,这样一方面实现了存储容量的水平扩展(增加新的节点后,会自动将其他节点上的 Region 调度过来),另一方面也实现了负载均衡(不会出现某个节点有很多数据,其他节点上没什么数据的情况)。同时为了保证上层客户端能够访问所需要的数据,系统中也会有一个组件(PD)记录 Region 在节点上面的分布情况,也就是通过任意一个 Key 就能查询到这个 Key 在哪个 Region 中,以及这个 Region 目前在哪个节点上(即 Key 的位置路由信息)。至于负责这两项重要工作的组件(PD),会在后续介绍。
对于第二点,TiKV 是以 Region 为单位做数据的复制,也就是一个 Region 的数据会保存多个副本,TiKV 将每一个副本叫做一个 Replica。Replica 之间是通过 Raft 来保持数据的一致,一个 Region 的多个 Replica 会保存在不同的节点上,构成一个 Raft Group。其中一个 Replica 会作为这个 Group 的 Leader,其他的 Replica 作为 Follower。所有的读和写都是通过 Leader 进行,读操作在 Leader 上即可完成,而写操作再由 Leader 复制给 Follower。 大家理解了 Region 之后,应该可以理解下面这张图:
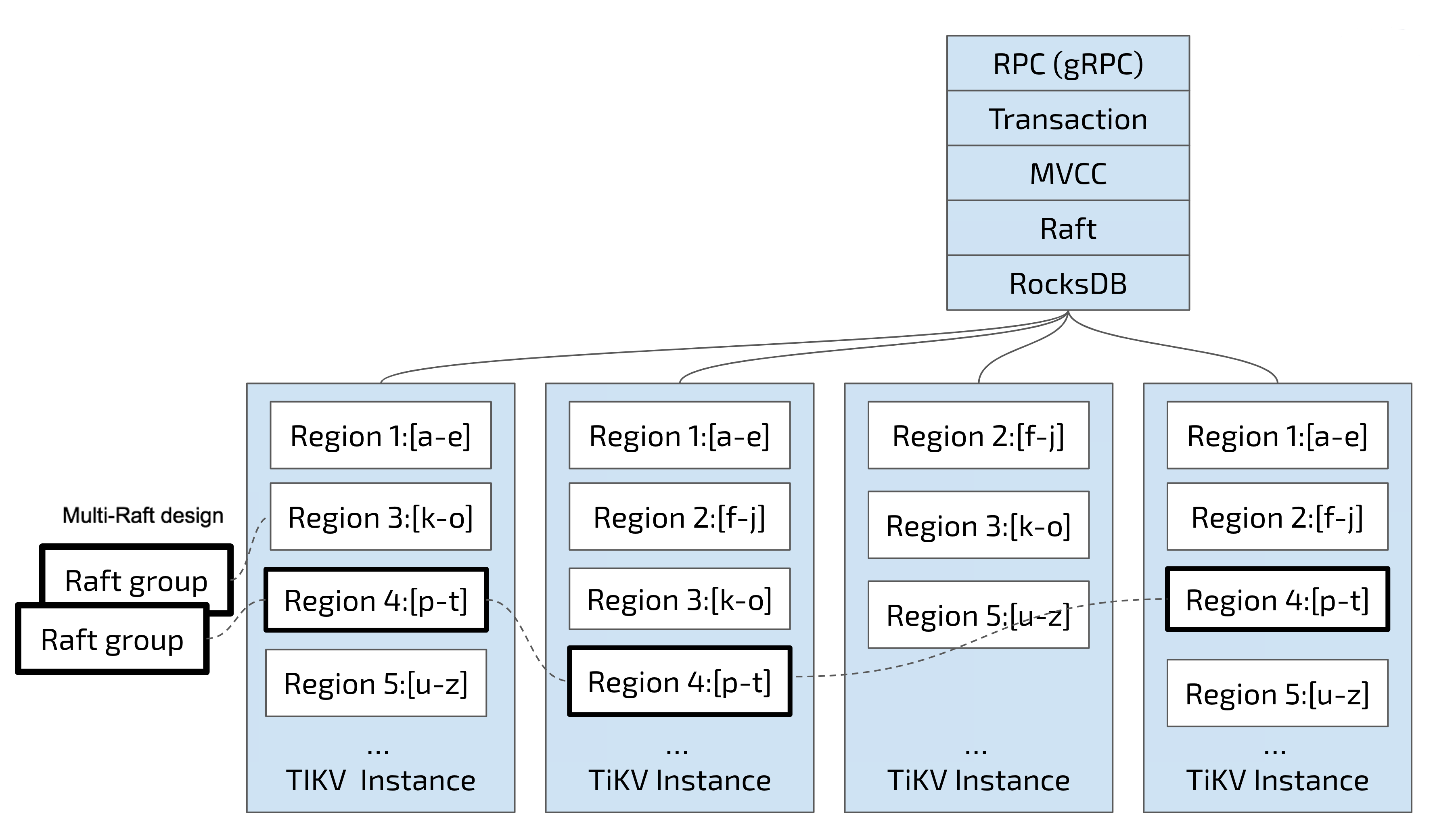
以 Region 为单位做数据的分散和复制,就有了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。
2.5 MVCC
很多数据库都会实现多版本并发控制(MVCC),TiKV 也不例外。设想这样的场景,两个客户端同时去修改一个 Key 的 Value,如果没有数据的多版本控制,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。 TiKV 的 MVCC 实现是通过在 Key 后面添加版本号来实现,简单来说,没有 MVCC 之前,可以把 TiKV 看做这样的:
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1_Version3 -> Value
Key1_Version2 -> Value
Key1_Version1 -> Value
……
Key2_Version4 -> Value
Key2_Version3 -> Value
Key2_Version2 -> Value
Key2_Version1 -> Value
……
KeyN_Version2 -> Value
KeyN_Version1 -> Value
……
注意,对于同一个 Key 的多个版本,我们把版本号较大的放在前面,版本号小的放在后面(回忆一下 Key-Value 一节我们介绍过的 Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以通过 Key 和 Version 构造出 MVCC 的 Key,也就是 Key_Version。然后可以直接通过 RocksDB 的 SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
2.6 分布式 ACID 事务
TiKV 的事务采用的是 Google 在 BigTable 中使用的事务模型:Percolator,TiKV 根据这篇论文实现,并做了大量的优化。这个在后续的章节中会有详细的介绍。
在 TiKV 层的事务 API 的语义类似下面的伪代码:
tx = tikv.Begin()
tx.Set(Key1, Value1)
tx.Set(Key2, Value2)
tx.Set(Key3, Value3)
tx.Commit()
这个事务中包含3条 Set 操作,TiKV 能保证这些操作要么全部成功,要么全部失败,不会出现中间状态或脏数据。 就如前面提到的,TiDB 的 SQL 层会将 SQL 的执行计划转换成多个 KV 操作,对于上层的同一个业务层的 SQL 事务,在底层也是对应一个 KV 层的事务,这是 TiDB 实现 MySQL 的事务语义的关键。