tidb-in-action
9.1 TiDB HTAP 的特点
HTAP 是 Hybrid Transactional / Analytical Processing 的缩写。这个词汇在 2014 年由 Gartner 提出。传统意义上,数据库往往专为交易或者分析场景设计,因而数据平台往往需要被切分为 TP 和 AP 两个部分,而数据需要从交易库复制到分析型数据库以便快速响应分析查询。而新型的 HTAP 数据库则可以同时承担交易和分析两种智能,这大大简化了数据平台的建设,也能让用户使用更新鲜的数据进行分析。
作为一款优秀的 HTAP 数据数据库,TiDB 除了优异的交易处理能力,也具备了良好的分析能力。
1. 数据库设计上的矛盾点
传统交易数据库在处理混合负载时有如下两个核心矛盾无法解决:
- 行存对于分析场景不友好
- 无法做到业务负载隔离
为了解决上述两个核心矛盾,作为 TiKV 扩展的列存储方案 TiFlash 应运而生,它有如下优势:
- 可更新列式存储设计,在提供高速更新能力的同时,提供高效的批量读取性能
- 配合源于 ClickHouse 的极致向量化计算引擎,更少的废指令,SIMD 加速
- 不影响 TiKV 稳定运行的前提下,提供一致性的读取保证,以及实时查询业务数据的能力
- TiDB 可以智能选择使用行存或者列存
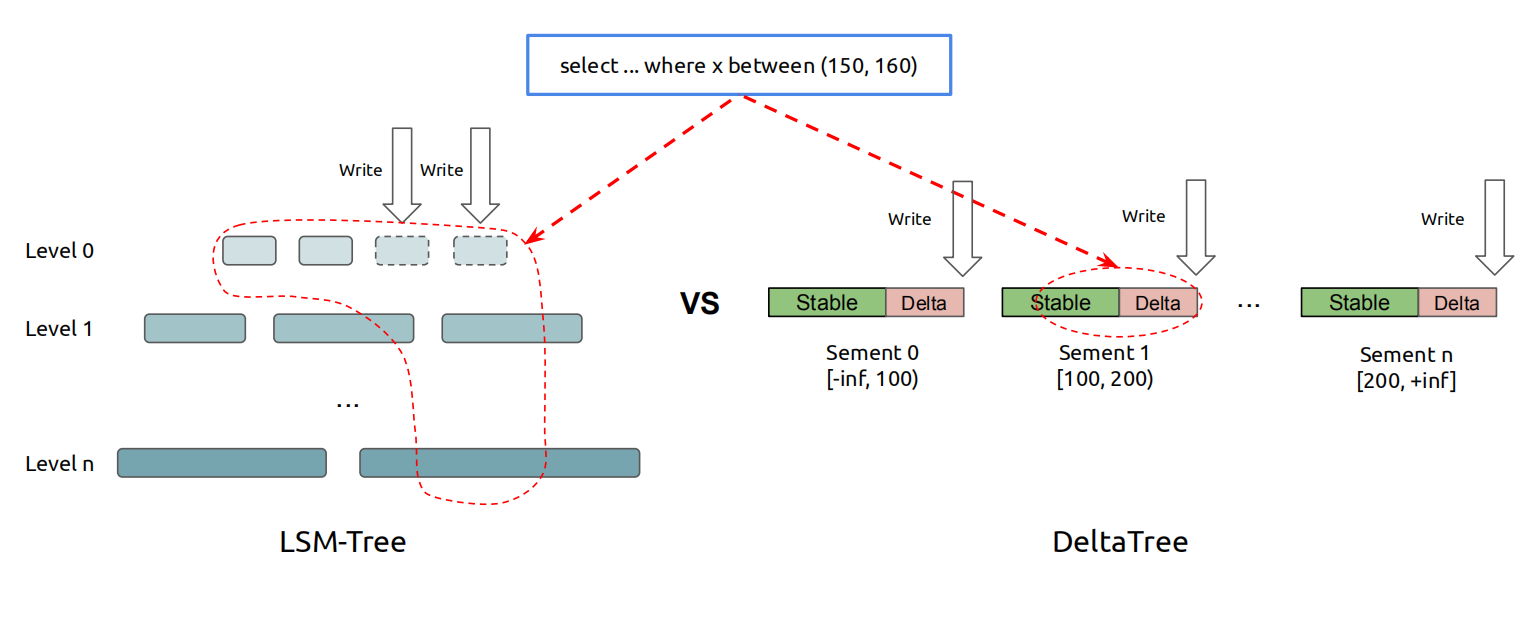
2. 可更新列式存储引擎 Delta Tree
TiFlash 配备了可更新的列式存储引擎。列存更新的主流设计是 Delta Main 方式,基本思想是,由于列存块本身更新消耗大,因此往往设计上使用缓冲层容纳新写入的数据。然后再逐渐和主列存区进行合并。TiFlash 也使用了类似的 Delta Main 设计,从这个意义而言,LSM 也可用于列存更新。具体来说,Delta Tree 利用树状结构和双层 LSM 结合的方式处理更新,以规避单纯使用 LSM 设计时需要进行的多路归并。通过这种方式,TiFlash 在支持更新的同时也具备高速的读性能。
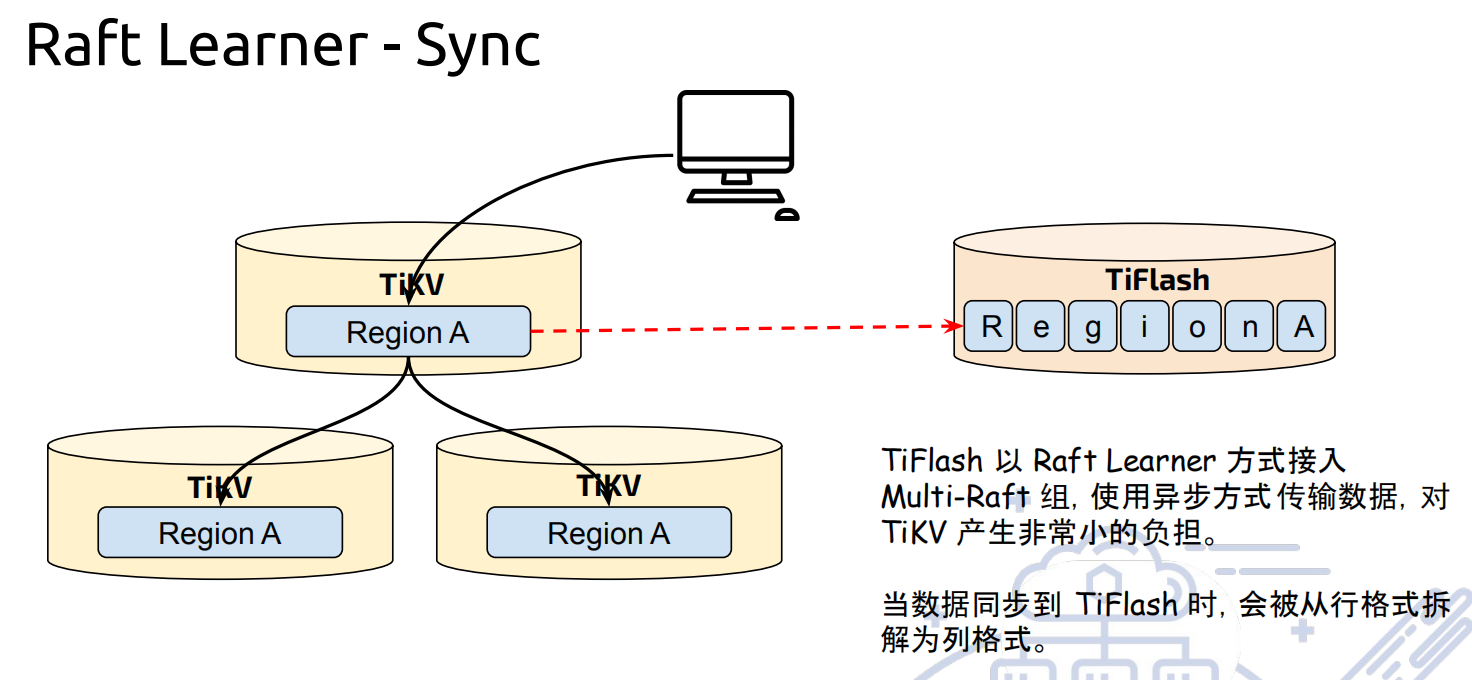
3. 实时且一致的复制体系
TiFlash 无缝融入整个 TiDB 的 Multi-Raft 体系。它通过 Raft Learner 进行数据复制,通过这种方式 TiFlash 的稳定性并不会对 TiKV 产生影响。例如 TiFlash 节点宕机或者网络延迟,TiKV 仍然可以继续运行无碍且不会因此产生抖动。于此同时,该复制协议允许在读时进行极轻量的校对以确保数据一致性。另外,TiFlash 可以与 TiKV 一样的方式进行在线扩容缩容,且能自动容错以及负载均衡。
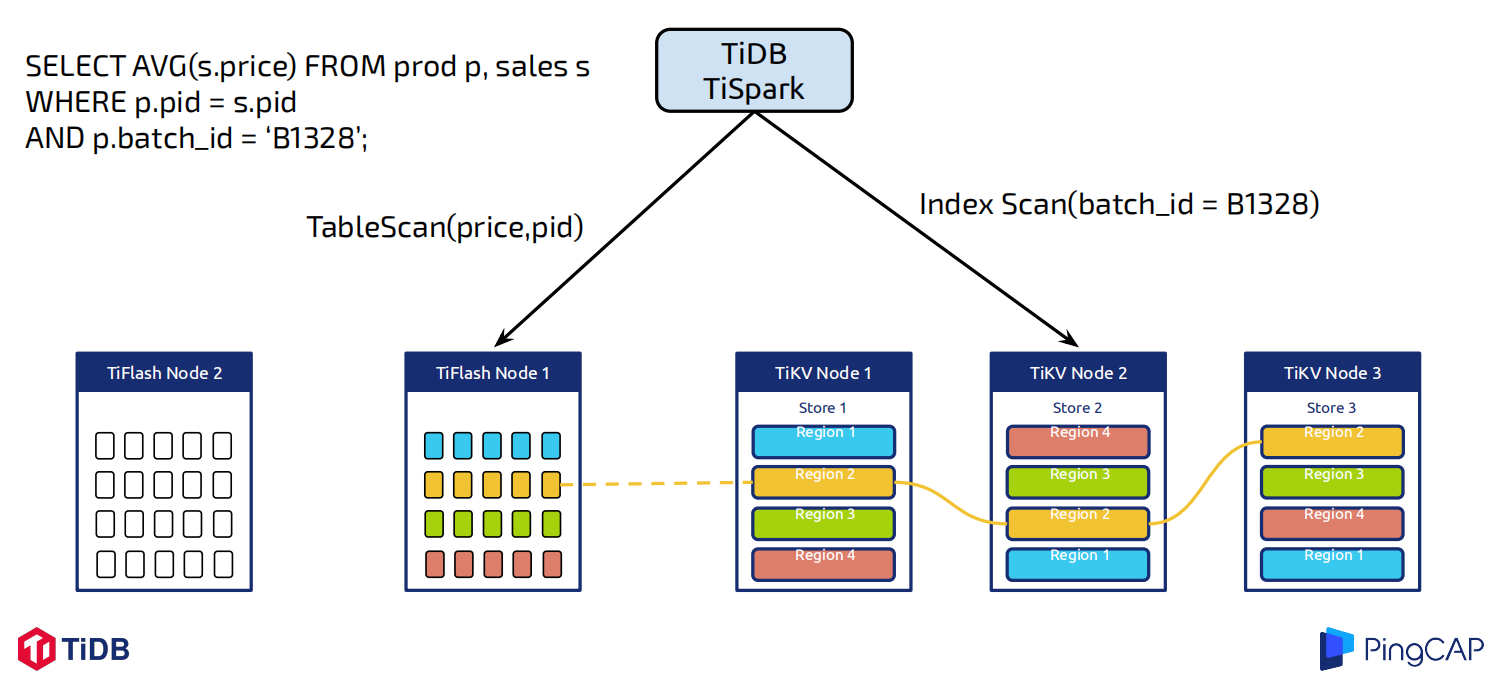
4. 完整的业务隔离
由于 TiFlash 的列存复制设计,用户可以选择单独使用与 TiKV 不同的另一组节点存放列存数据。另外不论是 TiDB 还是 TiSpark,计算层都可以强制选择行存或者列存,这样用户可以毫无干扰地查询在线业务数据,为实时 BI 类应用提供强力支持。
智能的行列混合模式
如果不使用上述隔离模式进行查询,TiDB 也可经由优化器自主选择行列。这套选择的逻辑与选择索引类似:优化器根据统计信息估算读取数据的规模,并对比选择列存与行存访问开销,做出最优选择。通过这种模式,用户可以在同一套系统方便地同时满足不同特型的业务需求。例如一套物流系统需要同时支持点查某订单信息,也需要进行大规模聚合统计某一时间段内货物派送和分发的汇总信息,利用 TiDB 的行列混合体系可以很简单实现,且完全无需担心不同系统间数据复制带来的不一致。
5. 更快的业务接入速度
同时兼备行存和列存的优势,让用户能更容易地接入业务。利用传统手段,用户往往需要将在线数据导出到分析平台才能进行分析,而这中间涉及了复杂的 ETL 或者数据传输管道维护,另外不同系统之间数据如何保持一致,如何进行格式转换也是很费思量的事情。因此,整个业务接入过程往往要花费数天甚至数周。而使用 TiDB 则可以帮助你大大简化这个过程。
6. 未来规划
TiFlash 在未来计划支持不依赖 TiKV 的直接写入,当做 TiKV 的冷备存储等功能,这样 TiDB HTAP 体系将变得更加完整。