tidb-in-action
9.2 TiFlash 架构与原理
相比于行存,TiFlash 根据强 Schema 按列式存储结构化数据,借助 ClickHouse 的向量化计算引擎,带来读取和计算双重性能优势。相较于普通列存,TiFlash 则具有实时更新、分布式自动扩展、SI(Snapshot Isolation)隔离级别读取等优势。本章节将从架构和原理的角度来解读 TiFlash。
9.2.1 基本架构
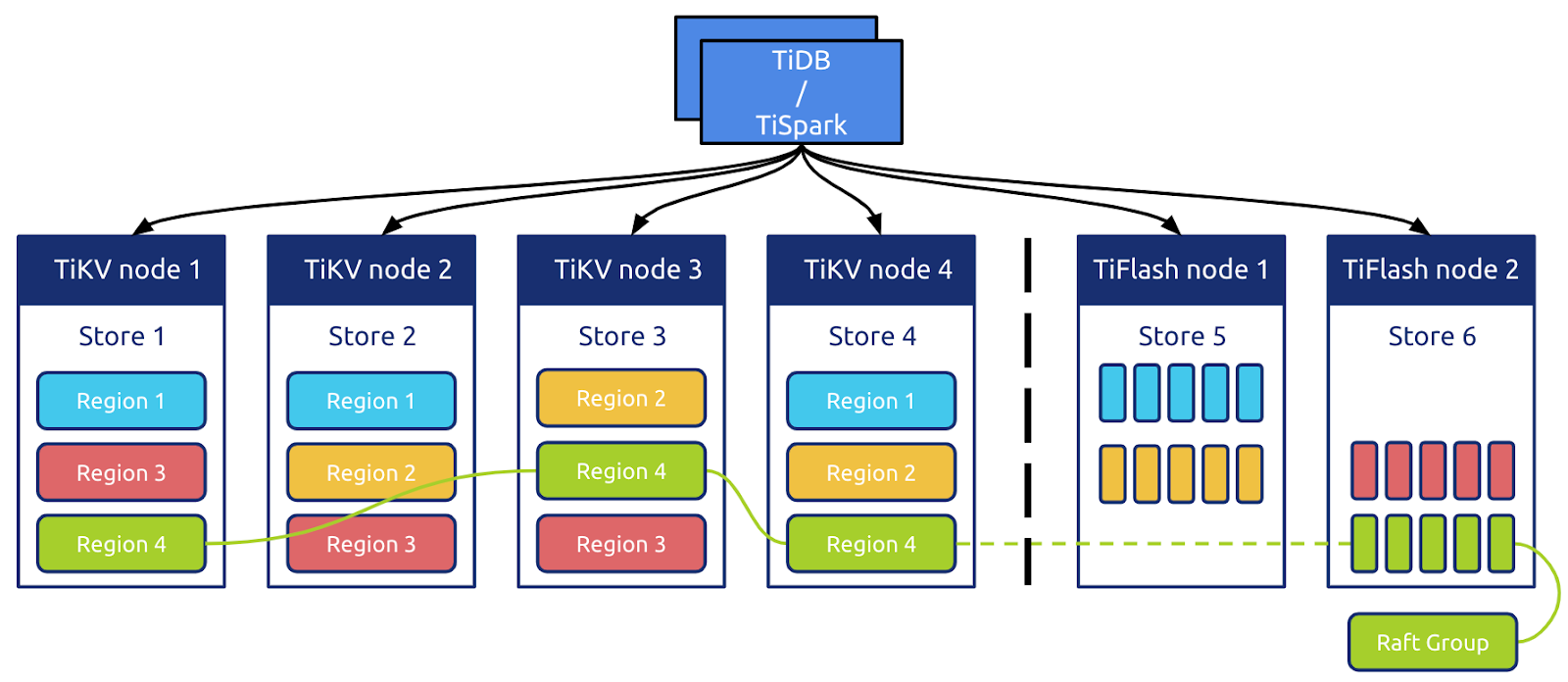
TiFlash 引擎补全了 TiDB 在 OLAP 方面的短板。TiDB 可通过计算层的优化器分析,或者显式指定等方式,将部分运算下推到对应的引擎,达到速度的提升。值得一提的是,在表关联场景下,即便 TiFlash 架构没有 MPP 相关功能,借助 TiDB 的查询优化器、布隆过滤器下推和表广播等手段,相当比例的关联场景仍可享受 TiFlash 加速。
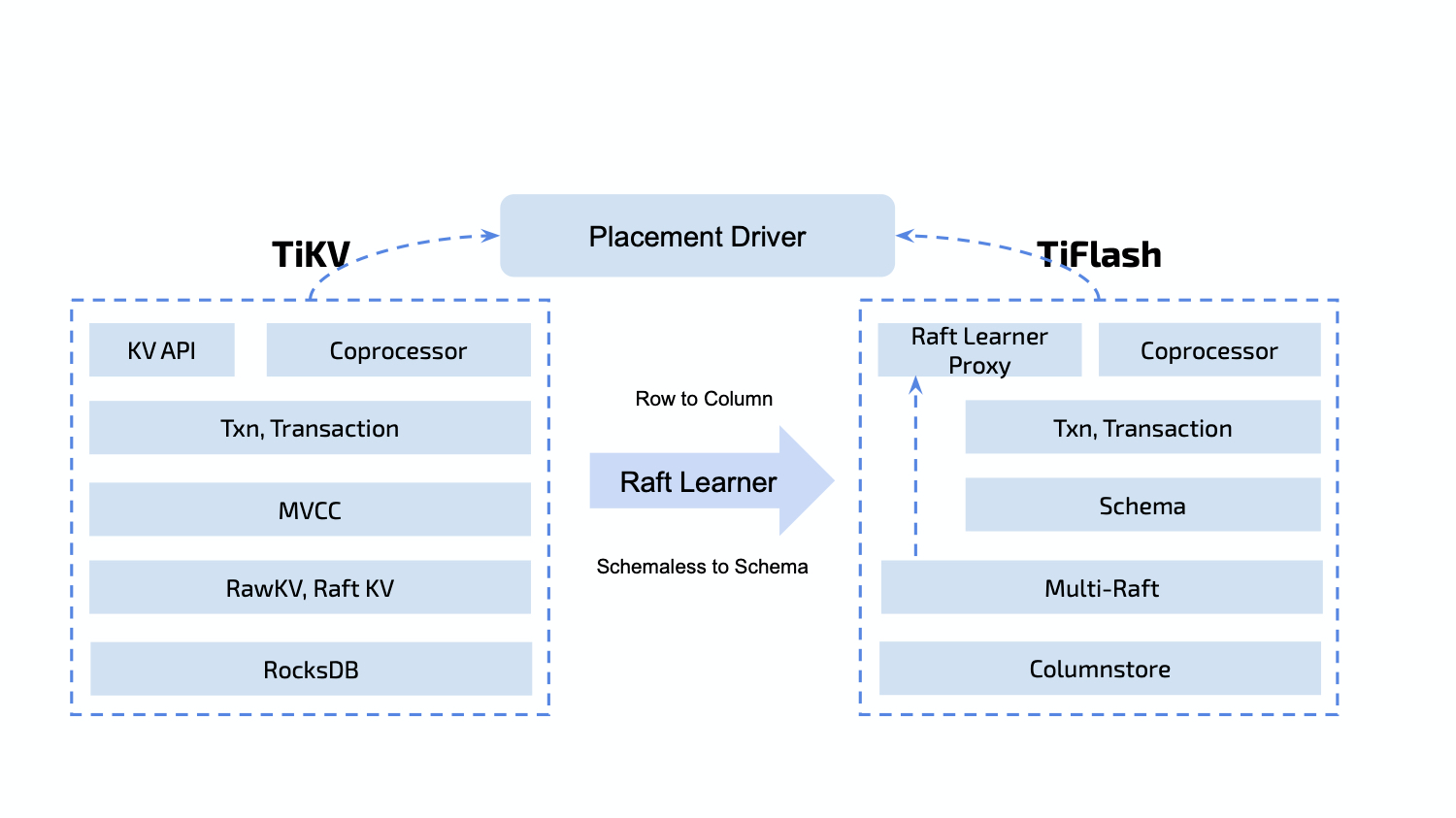
如上图所示,TiFlash 能以 Raft Learner Store 的角色无缝接入 TiKV 的分布式存储体系。TiKV 基于 Key 范围做数据分片并将一个单元命名为 Region,同一 Region 的多个 Peer(副本)分散在不同存储节点上,共同组成一个 Raft Group。每个 Raft Group 中,Peer 按照角色划分主要有 Leader、Follower、Learner。在 TiKV 节点中,Peer 的角色可按照一定的机制切换,但考虑到底层数据的异构性,所有存在于 TiFlash 节点的 Peer 都只能是 Learner(在协议层保证)。TiFlash 对外可以视作特殊的 TiKV 节点,接受 PD 对于 Region 的统一管理调度。TiDB 和 TiSpark 可按照和 TiKV 相同的 Coprocessor 协议下推任务到 TiFlash。
在 TiDB 的体系中,每个 Table 含有 Schema、Index(索引)、Record(实际的行数据) 等内容。由于 TiKV 本身没有 Table 的概念,TiDB 需要将 Table 数据按照 Schema 编码为 Key-Value 的形式后写入相应 Region,通过 Multi-Raft 协议同步到 TiFlash,再由 TiFlash 根据 Schema 进行解码拆列和持久化等操作。
9.2.2 原理
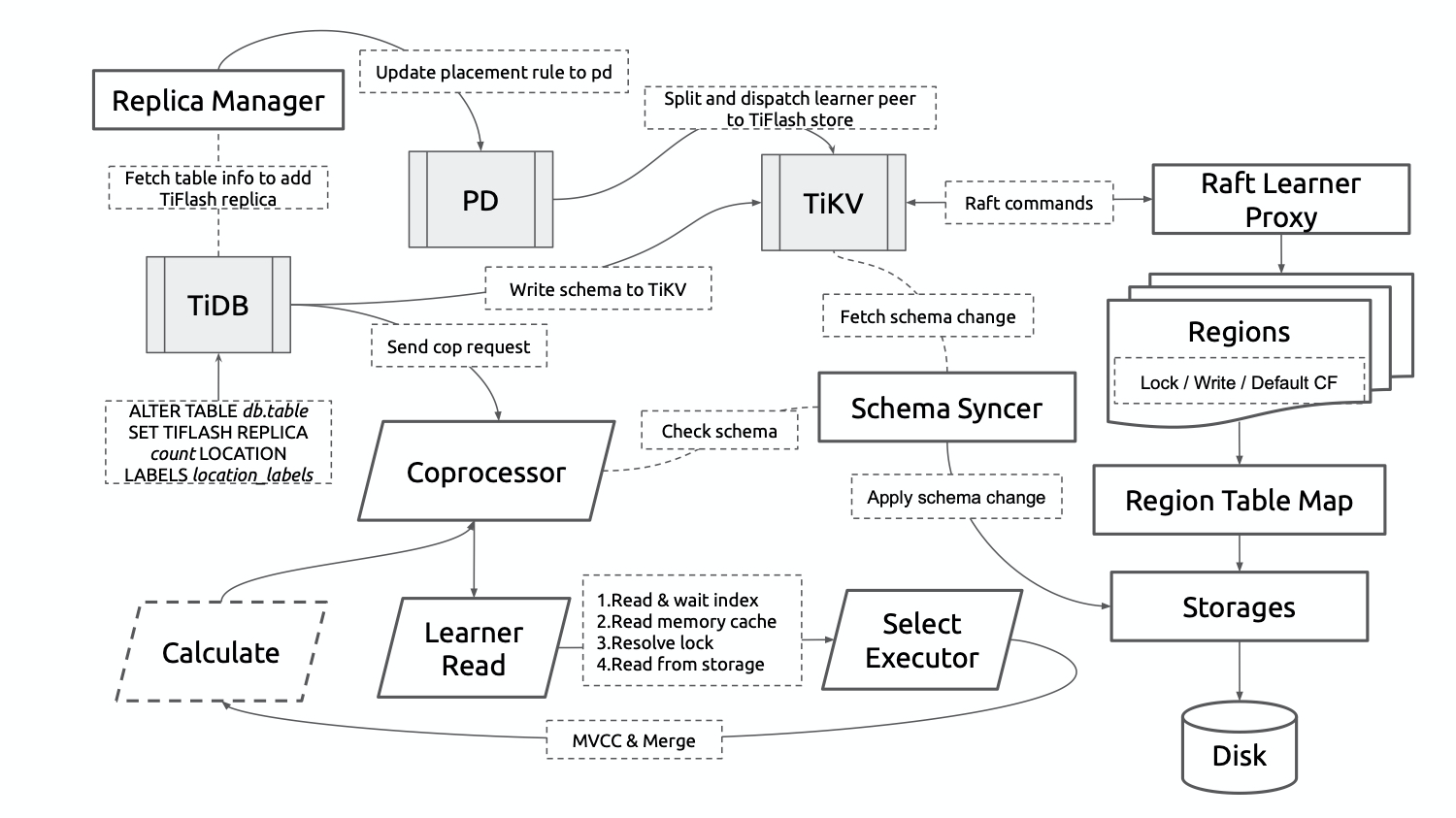
这是一张 TiFlash 数据同步到读取的基本流程架构图,以下将按照大类模块分别简单介绍。
1. Replica Manager
Index 这种主要面向点查的结构对于 TiFlash 的列式存储是没有意义的。为了避免同步冗余数据并实现按 Table 动态增删 TiFlash 列存副本,需要借助 PD 来有选择地同步 Region。
在同一个集群内的 TiFlash 节点会利用 PD 的 ETCD 选举并维护一个 Replica Manager 来负责与 PD 和 TiDB 交互。当感知到 TiDB 对于 TiFlash 副本的操作后(DDL 语句),会将其转化为 PD 的 Placement Rule,通过 PD 令 TiKV 分裂出指定 Key 范围的 Region,为其添加 Learner Peer 并调度到集群中的 TiFlash 节点。此外,当 Table 的 TiFlash 副本尚未可用时,Replica Manager 还负责向各个 TiFlash 节点收集 Table 的数据同步进度并上报给 TiDB。
2. Raft Learner Proxy
基于 Raft Learner 的数据同步机制是整个 TiFlash 存储体系的基石,也是数据实时性、正确性的根本保障。Region 的 Learner Peer 除了不参与投票和选举,仍要维护与其他 TiKV 节点中相同的全套状态机。因此,TiKV 被改造成了一个 Raft Proxy 库,并由 Proxy 和 TiFlash 协同维护节点内的 Region,其中实际的数据写入发生在 TiFlash 侧。
作为固定存在的 Learner,TiFLash 可以进行数据进行二次加工而不用担心对其他节点产生影响。TiFlash 在执行 Raft 命令时就可以做到剔除无效数据,将未提交的数据按 Schema 预解析等优化。同时 TiFlash 实现了对于 Raft 命令的幂等回放以及引擎层的幂等写,可以不记录 WAL 且只在必要的时刻做针对性的持久化,从而简化模型并降低了风险。
TiDB 的事务实现是基于 Percolator 模型的,映射到 TiKV 中则是对 3 个 CF(Column Family) 数据的读写:Write、Default、Lock。TiFlash 也在每个 Region 内部对此做了抽象,不同的是对于 TiFlash 而言,数据写入 CF 只能作为中间过程,最终持久化到存储层需要找到 Region 对应的 Table 再根据 Schema 进行行列结构转换。
3. Schema Syncer
每个 TiFlash 节点都会实时同步 TiDB 的最新的表 Schema 信息。TiFlash 兼容 TiDB 体系的在线 DDL,对经常需要做表结构修改的业务非常友好,例如增、删、改字段等操作都不影响在线业务。
4. Learner Read / Coprocessor
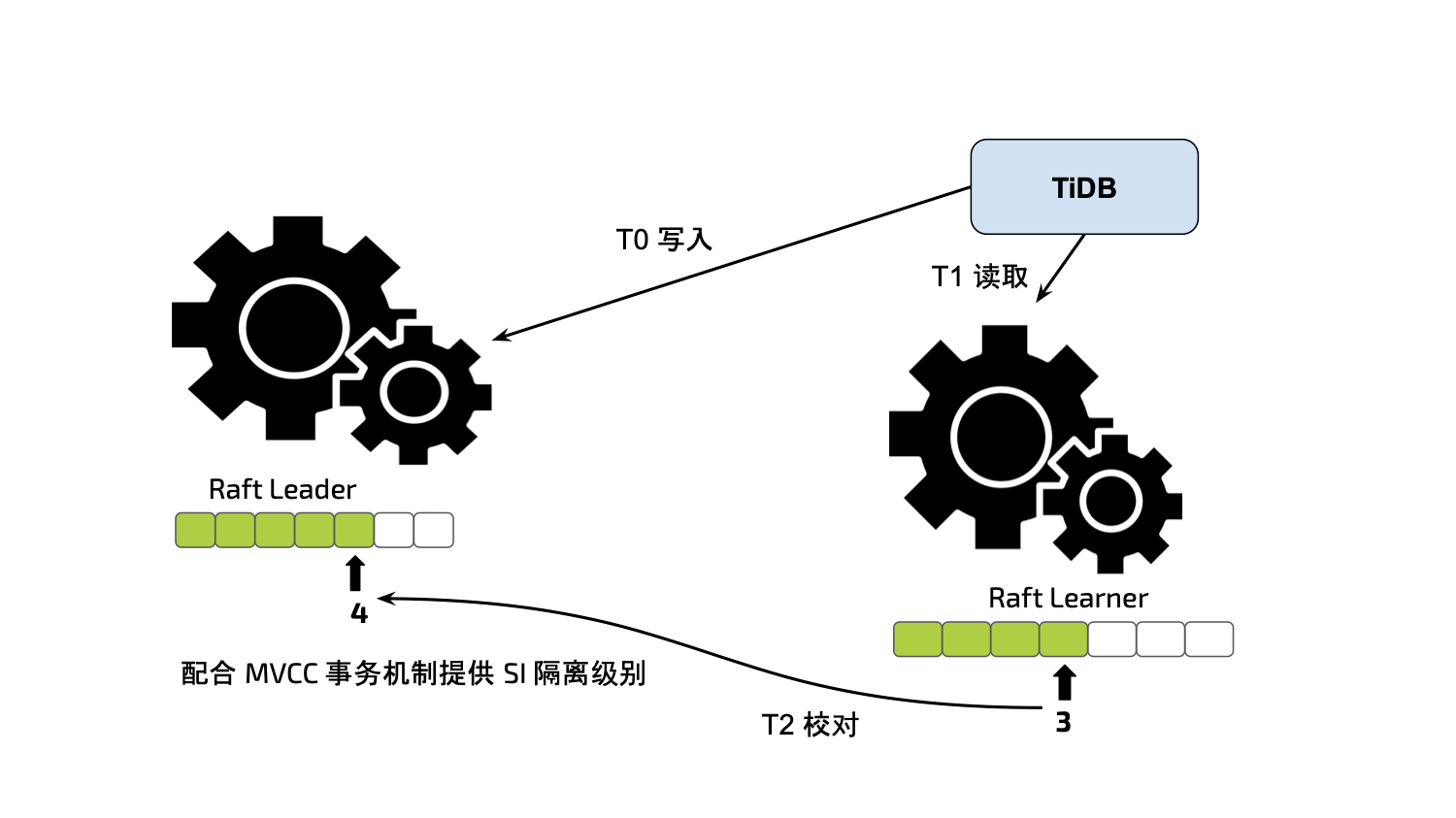
无论是通过 CH 客户端、TiSpark、CHSpark 还是 TiDB 向 TiFlash 发起查询,都需要 Learner Read 来确保外部一致性。在同一个 Raft Group 中,Index 是永续递增的(任何 Raft 命令都会对其产生修改),可被视作乐观锁。Region 本身含有 Version 和 Conf Version 两种版本号,当发生诸如 Split/Merge/ChangePeer 等操作时,版本号均会产生相应的变化。
所有的查询都需要由上层拆分为一个或多个 Region 的读请求,需要包含 Region 的两种版本号(可从 PD 或 TiKV 获取),Timestamp(用于 Snapshot Read 的时间戳,从 PD 获取),以及 Table 相关信息(Schema Version 从 TiDB 获取)。单次读请求可大致分为以下步骤:
- 校验并更新本节点的 Schema
- 向 Region 的 Leader Peer 获取最新的 Index,等待当前节点中 Learner 的 Applied Index 追上
- 校对 Version 和 Conf Version,检查 Lock CF 中的锁信息
- 读取内存中的半结构化数据和存储引擎中 Region 范围对应的结构化数据
- 按照 Timestamp 进行 Snapshot Read 和多路合并
- Coprocessor 计算(主要借助 ClickHouse 的向量化计算引擎)
9.2.3 TiFlash 对 OLAP 查询加速
OLAP 类的查询通常具有以下几个特点:
- 每次查询读取大量的行,但是仅需要少量的列
- 宽表,即每个表包含着大量的列
- 查询通过一张或多张小表关联一张大表,并对大表上的列做聚合
TiFlash 列存引擎针对这类查询有较好的优化效果:
(1) I/O 优化
- 每次查询可以只读取需要的列,减少了 I/O 资源的使用
- 同列数据类型相同,相较于行存可以获得更高的压缩比
- 整体的 I/O 减少,令内存的使用更加高效
(2) CPU 优化
- 列式存储可以很方便地按批处理字段,充分利用 CPU Cache 取得更好的局部性
- 利用向量化处理指令并行处理部分计算
9.2.4 TiKV 与 TiFlash 配合
TiFlash 可被当作列存索引使用,获得更精确的统计信息。对于关联查询来说,点查相关的任务可以下推到 TiKV,而需要关联的大批量聚合查询则会下推到TiFlash,通过两个引擎的配合,达到更快的速度。
9.2.5 总结与展望
TiFlash 是 TiDB HTAP 之路上的全新实践。这套架构体系也将伴随生产环境的使用不断演化发展,进而为用户解决更多问题。