tidb-in-action
2.1.2 CDC 工作原理
TiCDC(TiDB Change Data Capture)是用来识别、捕捉和输出 TiDB/TiKV 集群上数据变更的工具系统。它既可以作为 TiDB 增量数据同步工具,将 TiDB 集群的增量数据同步至下游数据库,也提供开放数据协议,支持把数据发布到第三方系统。相较于 TiDB Binlog,TiCDC 不依赖 TiDB 事务模型保证数据同步的一致性,系统可水平扩展且天然支持高可用。
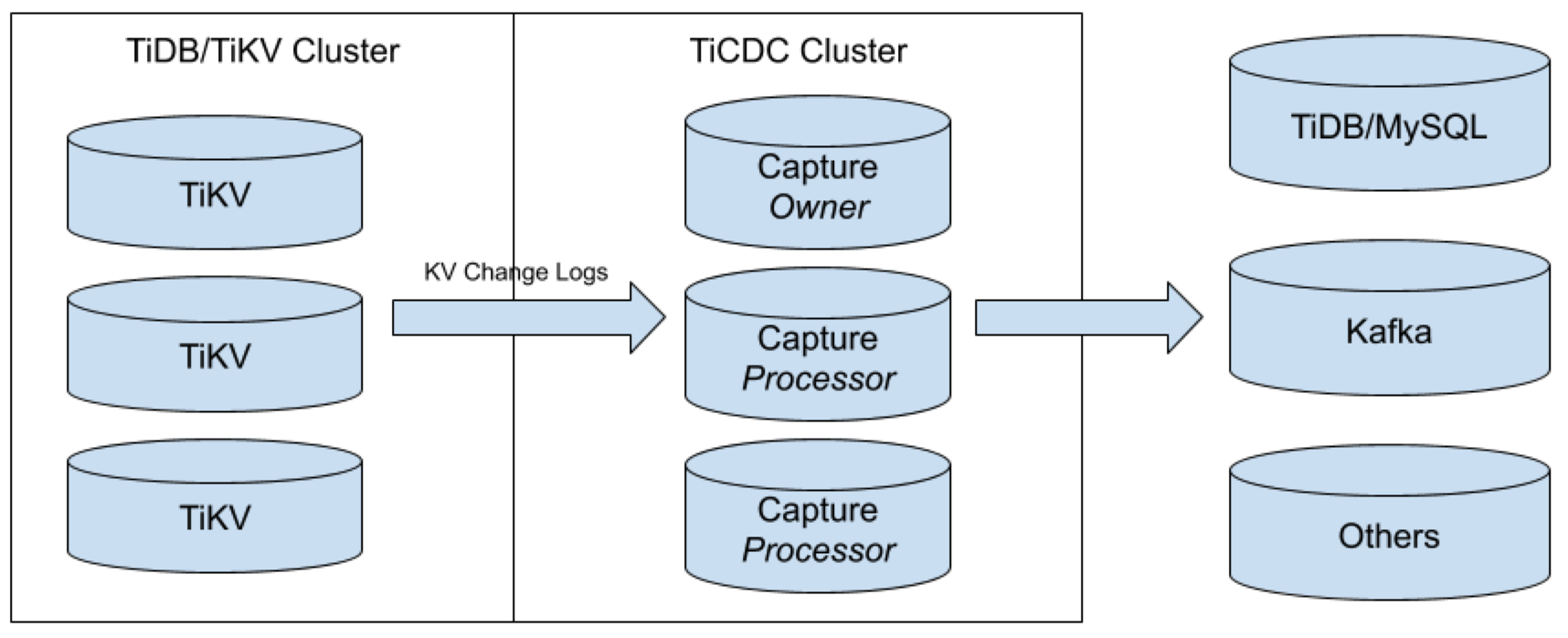
TiCDC 的系统架构如上图所示:
-
TiKV:输出 KV 变更日志(KV Change Logs)。KV 变更日志是TiKV 生成的 row changed events,隐藏了大部分内部实现细节。TiKV 负责拼装 KV 变更日志,并输出到 TiCDC 集群。
- Capture:TiCDC 的运行进程。一个 TiCDC 集群通常由多个 capture 节点组成,每个节点负责拉取一部分 KV 变更日志,排序后输出到下游组件。一个TiCDC 集群里有两种 capture 角色:owner 和 processor。
- 一个 TiCDC 集群有且仅有一个 owner,它负责集群内部调度。若 owner 出现异常,则其它 capture 节点会自发选举出新的 owner。
- processor 在实现上是 capture 内部的逻辑线程。一个 capture 节点可以运行多个 processor,每个 processor 负责同步若干个表的数据变更。processor 所在的 capture 节点若出现异常,则 TiCDC 集群会把同步任务重新分配给其它 capture 节点。
- capture 运行过程中的一些数据会持久化到 PD 内部的 etcd 中,这些数据包括同步任务的配置和状态、各 capture 节点的信息、owner 选举信息以及 processor 的同步状态等。
- 前面多次提到的“同步任务”,也被称作 change feed,指的是由一个用户启动的从上游 TiDB 同步数据变更到下游组件的任务。用户在创建同步任务时需要指定上下游的连接方式,列出需要同步的数据库和表名,还可以指定从上游哪个 TSO 开始同步 KV 变更日志。TiCDC 集群支持创建并运行多个同步任务,并同时向多个不同的下游组件输出变更日志。通常一个同步任务会被拆分为多个子任务,每个子任务也被称作 task。每个子任务负责若干个表的变更日志同步,这些子任务会分发到不同 capture 节点并行处理。
- Sink:TiCDC 内部负责将已经排序的数据变更同步到下游的组件。TiCDC 支持同步数据变更到多种下游组件。
- 支持同步数据到 TiDB 和 MySQL。为保证数据正确性,表结构定义须满足两个条件:必须要有主键或者唯一索引;若不存在主键,则构成唯一索引的每一个字段都应该被明确定义为
NOT NULL。 - 支持按照 TiCDC 开发数据协议(open protocol)输出数据到 Kafka。其他系统可以订阅 Kafka 上的数据变更。
- 未来将支持输出数据变更到多种文件存储系统上。
- 支持同步数据到 TiDB 和 MySQL。为保证数据正确性,表结构定义须满足两个条件:必须要有主键或者唯一索引;若不存在主键,则构成唯一索引的每一个字段都应该被明确定义为