tidb-in-action
2.4.1 Dumpling 工作原理
1. 背景介绍
首先介绍一下 Dumpling 的诞生背景,在 Dumpling 诞生之前 PingCAP 提供了 Mydumper 的 fork 版本作为 TiDB 逻辑备份工具。随着 TiDB 生态的发展,Mydumper 由于种种先天不足,无法进一步满足实际应用中的需要。Mydumper 的不足主要有以下几点:
- 导出的数据格式无法满足 TiDB Lighting 数据导入工具的快速解析需要
- Mydumper 官方仓库年久失修,TiDB 并不倾向于在 fork 版本中继续提供新特性
- Mydumper 使用 C 语言及 GLib 开发,难以集成到与 Go 语言为主的 TiDB 生态工具,例如 DM 等
- Mydumper 本身采用的开源协议与 TiDB 所使用的开源协议不兼容
基于这些原因考虑,以 Dumpling 取而代之成为了更好的选择。Dumpling 将提供以下几个特性:
- 完全采用 Golang,与 TiDB 生态集成度高
- 能够提供 Mydumper 类似的功能,且支持并发高速导出 MySQL 协议兼容数据库数据
- 提供 SQL、CSV 等多种数据输出格式,以便于快速导出及导入
- 支持直接导出数据到云存储系统,比如 S3
2. 工作原理
一图胜千言,下面是 Dumpling 导出流程示意图:
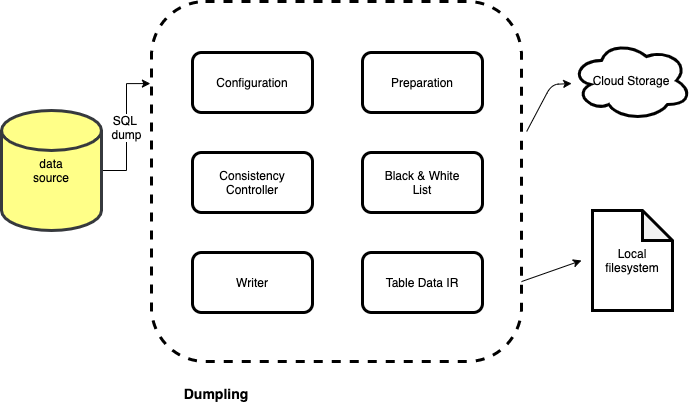
如图所示,Dumpling 分为六个比较重要的部分,分别负责配置解析、数据库信息预处理、一致性控制器、Black & White 列表、写控制器及表数据中间层表示。下面详细介绍一下各个部分的工作内容:
- 配置解析:处理用户通过命令行传入的参数
- 数据库信息预处理:在数据导出任务进行之前,获取数据库服务器版本、数据表、数据库视图等相关信息并进行预处理
- 一致性控制器:通过用户传入的一致性规则,在数据导出过程中保障数据一致性
- Black & White 列表:根据设置的规则过滤不需要导出的数据表
- 写控制器:负责将导出的数据写入到本地文件或云端存储系统
- 表数据中间表示层:中间表示层将数据表进行封装,提供一套 API 以供写控制器进行数据迭代写入