tidb-in-action
4.1 性能调优地图
作为一款分布式数据库,性能调优是 TiDB 中较为复杂且重要的部分。
下图展示 TiDB 各个模块地图,通过这张地图可以清晰展现 TiDB 如何处理一条 SQL。
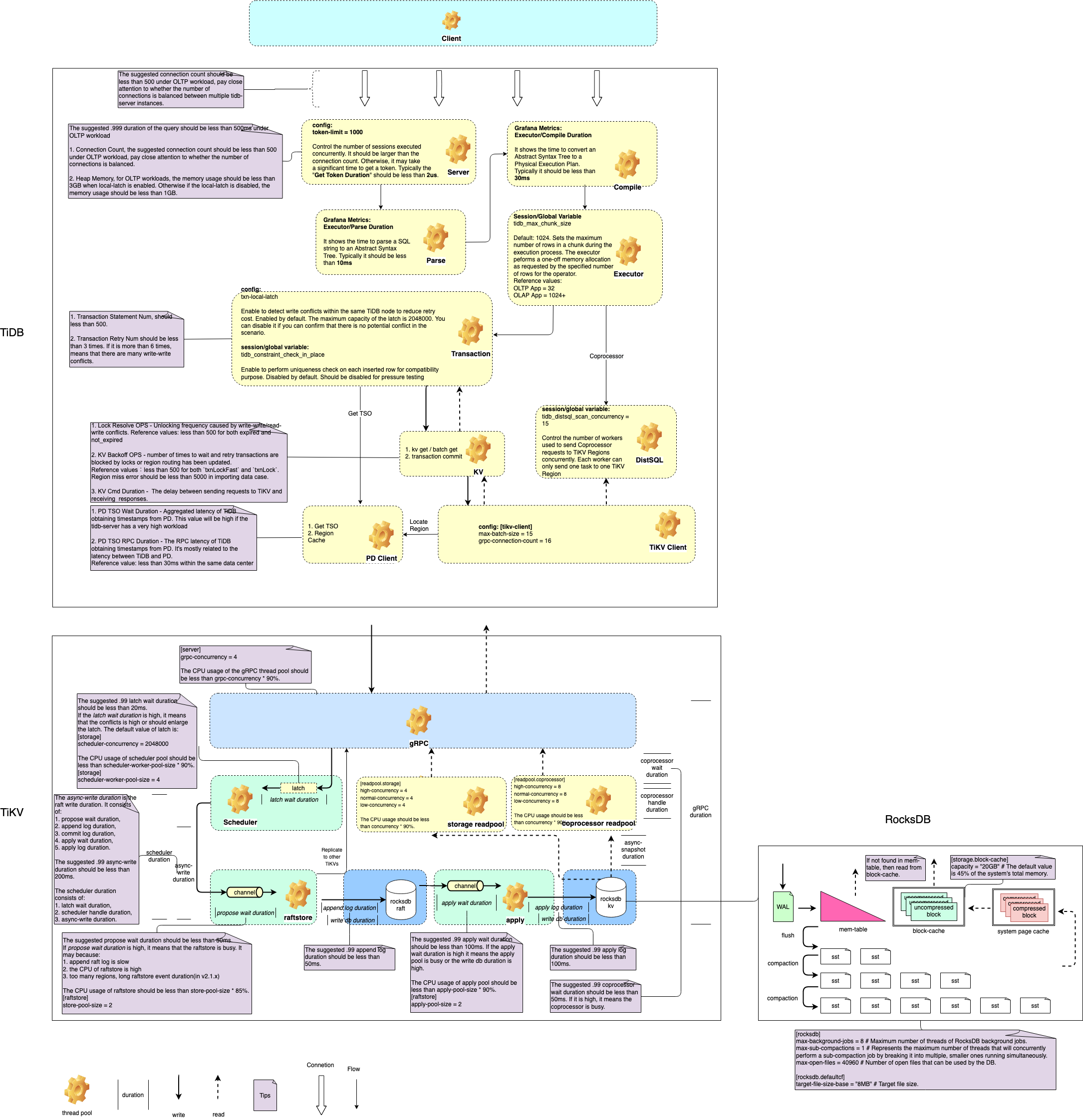
1. TiDB 地图说明
-
TiDB 的【Server】模块会为 MySQL 客户端的每一个连接创建一个 session 并且分配一个 token。可以通过 Connection Count 这项监控来查看 TiDB 的连接数,通常建议单个 TiDB 的连接数不超过 500 个
-
经由这个 session 发送到 TiDB 的 SQL 会在【Parse】中被转化为能够被 TiDB 所理解的语法树。转化时间可通过监控【Executor/Parse Duration】查看,通常应该在 10ms 以内
-
TiDB 根据语法树生成物理执行计划,决定选择哪些索引或者算子进行计算,这个过程被称作【Compile】。执行时间可通过监控【Executor/Compile Duration】查看
-
生成的物理执行计划会在【Executor】中进行执行
-
如果是 DML 语句,TiDB 会将用户更新的内容先缓存在【Transaction】模块中,等到用户执行事务的 Commit 时再进行两阶段提交,将结果写入到 TiKV
-
对于复杂查询请求,TiDB 会通过 【DistSQL】模块并行地向 TiKV 的多个 region 发送查询请求,然后再按照执行计划中的流程计算出查询结果来
-
TiDB 发送给 TiKV 的各种请求耗时可以通过监控【KV Request/KV Request Duration 99 by type】查看
-
-
TiDB 采用两阶段提交的事务模型。为此需要向 PD 请求一个全局逻辑时间戳 TSO,用来表明事务的开始时间与提交时间。为了不给 PD 造成过多的请求压力,TiDB 通过单个线程一次为多个事务分配时间
-
事务在 channel 中等待的时间为监控【PD Client/PD TSO Wait Duration】
-
TiDB 向 PD 请求时间戳的网络请求耗时为监控【PD Client/PD TSO RPC duration】
-
2. TiKV 地图说明
-
参考 读写流程分析 一章
-
TiKV 的主要由 6 个模块构成。分别是 gRPC、Scheduler、raftstore、apply、storage-readpool 以及 coprocessor-readpool
-
gRPC 是 TiKV 所有请求的入口,他会将外界的请求转发给各个模块
- 对于写事务的请求,会转发给 scheduler 线程
- 对于简单的读取请求 kv get 或者 kv batch get 会转发给 storage-readpool
- 对于 TiDB 的 DistSQL 发送过来的 Coprocessor 请求会转发给 coprocessor-readpool(在 4.0 中 storage-readpool 与 coprocessor-readpool 已经被合并为了同一个线程池)
- 如果是 PD 操作 region 的命令,则直接发送给 raftstore 线程
-
scheduler 负责检测事务冲突,将复杂的事务操作转换为简单的 key-value 插入、删除,发送给 raftstore 线程
- scheduler 线程执行各个命令的时间可以通过监控【Scheduler-/Scheduler command duration】查看。例如,Prewrite 请求的执行时间在【Scheduler-prewrite】面板
- 写请求完成 raft 日志复制,到写入 RocksDB 的全部时间可以通过监控【Storage/async write duration】查看
-
raftstore 负责执行 raft 日志复制,将数据复制给多个副本。当日志在多个副本上达成一致后,会发送给 apply 线程
- 写请求消耗在 raftstore 线程的时间为【Raft IO/Commit log duration】(raft 日志在多数副本上达成一致所需的时间)与【Raft Propose/Propose wait duration】(在队列中等待被处理的时间)之和
-
apply 线程负责将 scheduler 线程的 key-value 操作写入 RocksDB。然后通知 gRPC 线程返回结果给客户端
- 写请求消耗在 apply 线程的时间为【Raft IO/Apply log duration】(从队列中取出,插入到 RocksDB 的时间)与【Raft Propose/Apply wait duration】(在队列中等待被处理的时间)之和
-
storage-readpool 处理 kv get 以及 kv batch get 等简单的查询请求
-
coprocessor-readpool 处理复杂的范围查询以及表达式计算
-
-
TiKV 共持有两个 RocksDB 实例,一个用于 raftstore 线程记录 raft 日志与 raft 元信息。另一个用于记录用户写入的数据,以及 TiKV 事务中的锁信息
-
线程池调优请见 8.2.1 TiKV 线程池优化 章节
3. RocksDB 地图说明
RocskDB 是一款优秀的开源单机存储引擎,负责将 TiDB 的数据存储在磁盘上。
-
RocksDB 的三种基本文件格式
-
Memtable 是一种内存文件数据系统,新数据会被写进 Memtable
-
读取数据如果 Memtable 没有,会访问 Block-Cache
-
Block-Cache 默认设置为系统总内存的 45%,单机多实例的情况下,按照实例个数分配
-
-
WAL Write Ahead Log 写操作先写入 logfile,再写入 Memtable
-
SST 在 Memtable 写满以后,将数据写入磁盘中的 SST 文件,对应 logfile 里的 log 会被安全删除。
- SST 文件中的内容是有序的
- 根据一定的 Compaction 规则压缩数据
-