tidb-in-action
4.4 Prometheus 使用指南
本节将介绍监控工具 Prometheus 在 TiDB 中的应用,包括 Prometheus 本身的介绍以及如何通过 Prometheus 查看 TiDB 的监控和利用 Prometheus 的 alertmanager 进行告警。
4.4.1 Prometheus 简介
TiDB 使用开源时序数据库 Prometheus 作为监控和性能指标信息存储方案,使用 Grafana 作为可视化组件进行信息的展示。
Prometheus 狭义上是软件本身,即 prometheus server,广义上是基于 prometheus server 为核心的各类软件工具的生态。除 prometheus server 和 grafana 外,Prometheus 生态常用的组件还有 alertmanager、pushgateway 和非常丰富的各类 exporters。
prometheus server 自身是一个时序数据库,相比使用 MySQL 做为底层存储的 zabbix 监控,拥有非常高效的插入和查询性能,同时数据存储占用的空间也非常小。另外不同于 zabbix,prometheus server 中的数据是从各种数据源主动拉过来的,而不是客户端主动推送的。如果要使用 prometheus server 接收推送的信息,数据源和 prometheus server 中间需要使用 pushgateway。
Prometheus 监控生态非常完善,能监控的对象非常丰富。详细的 exporter 支持对象可参考官方介绍 exporters列表 。
Prometheus 可以监控的对象远不止官方 exporters 列表中的产品,有些产品原生支持不在上面列表,如 TiDB; 有些可以通过标准的 exporter 来监控一类产品,如 snmp_exporter; 还有些可以通过自己写个简单的脚本往 pushgateway 推送;如果有一定开发能力,还可以通过自己写 exporter 来解决。同时有些产品随着版本的更新,不需要上面列表中的 exporter 就可以支持,比如 ceph。
随着容器和 kurbernetes 的不断落地,以及更多的软件原生支持 Prometheus,相信很快 Prometheus 会成为监控领域的领军产品。
4.4.2 架构介绍
Prometheus 的架构图如下:
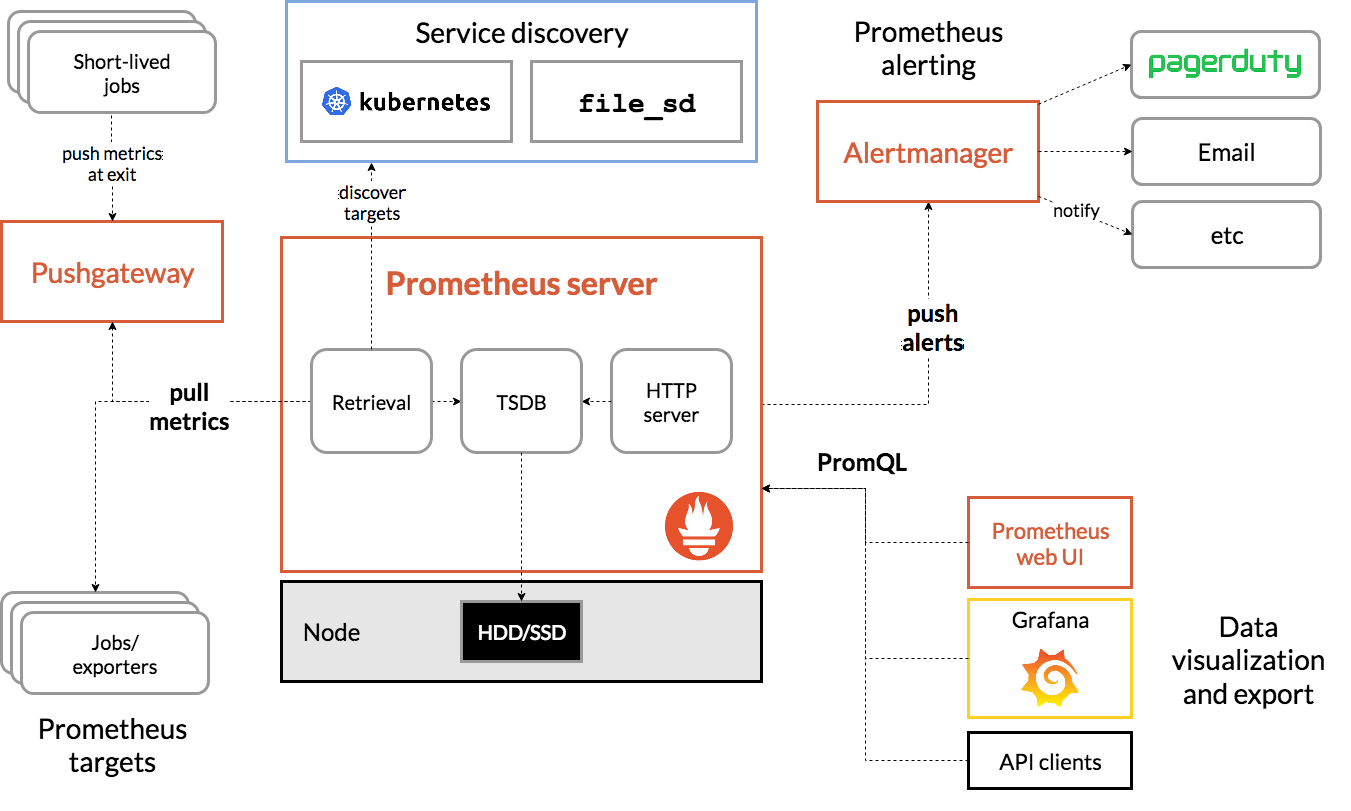
Prometheus 生态中 prometheus server 软件用于监控信息的存储、检索,以及告警消息的推送,是 Prometheus 生态最核心的部分。
Alertmanger 负责接收 prometheus server 推送的告警,并将告警经过分组、去重等处理后,按告警标签内容路由,通过邮件、短信、企业微信、钉钉、webhook 等发送给接收者。
大部分软件在用 Prometheus 作为监控时还需要部署一个 exporter 做为 agent 来采集数据,但是有部分软件原生支持 Prometheus,比如 TiDB 的组件,在不用部署 exporter 的情况下就可以直接采集监控数据。
PromQL 是 Prometheus 数据查询语言,用户可以通过 prometheus server 的 web UI,在浏览器上直接编写 PromQL 来检索监控信息。也可以将 PromQL 固化到 grafana 的报表中做动态的展示,另外用户还可以通过 API 接口做更丰富的自定义功能。
Prometheus 除了可以采集静态的 exporters 之外,还可要通过 service discovery 的方式监控各种动态的目标,如 kubernetes 的 node,pod,service 等。
除 exporter 和 service discovery 之外,用户还可以写脚本做一些自定义的信息采集,然后通过 push 的方式推送到 pushgateway,pushgateway 对于 prometheus server 来说就是一个特殊的 exporter,prometheus server 可以像抓取其他 exporters 一样抓取 pushgateway 的信息。
4.4.3 安装运行
Prometheus 可以运行在 kubernetes 中,也可以运行中虚拟机中。Prometheus 的大部分组件都已经有编译好的二进制文件和 docker 镜像。对于二进制文件,从官方网站下载解压后就可以启动运行,命令如下:
prometheus –config.file=conf/prometheus.yml
建议将二进制文件做成 systemd 的一个服务,这部分可以参考 TiDB 上运行 prometheus 的方式 。
1. Prometheus server 配置文件
prometheus server 的配置文件是 yaml 格式,由参数 –config.file 指定需要使用的配置文件。配置文件一般命名为 prometheus.yml。
配置文件示例
global:
scrape_interval: 15s
scrape_timeout: 10s
external_labels:
monitor: 'codelab-monitor'
rule_files:
- rules/centos7.rules.yml
- rules/mariadb.rules.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 21.129.127.3:9093
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
file_sd_configs:
- files:
- conf.d/centos.yml
配置文件说明:
- global: 指的是全局配置
- scrape_interval: 抓取目标监控信息的间隔,默认 15 秒
- scrape_timeout: 抓取时的超时时间,默认 10 秒
- external_labels: 额外添加的标签,这个标签可以在多个外部系统流转,如:federation, remote storage, Alertmanager
- rule_files: 这个写的是生成告警规则的配置文件,具体写法见 alertmanger 章节的介绍
- alerting: 这个是用来配置 alertmanager 地址,可以写多个 alertmanager 的地址
- scrape_configs: 从这开始,后面是采集对象的配置
- job_name:可以定义多个 job,每个 job 里有一类的采集对象
- static_configs: 后面可以写一些静态的监控对象
- targets: 要抓取的具体对象(instance)
- file_sd_configs: 如果监控对象过多,可使用这种方式写到独立的文件中
2. 告警规则配置示例
groups:
- name: alert.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1s
labels:
level: emergency
annotations:
summary: "该实例抓取数据超时"
description: "项目: , service: " 当前值
告警配置说明:
- groups: 标记当前所有的告警规划为同一组
- name: 这告警组的自定义名称
- alert:告警规则的名称
- expr:告警的表达式
- for: 问题发生后保持多长时间再推送给 client,调低该值可以提高告警的敏感度,调高会减少告警毛刺
- labels: 可以加一些自定义的键值对标签
- annotations: 可以加一些描述信息
4.4.4 Prometheus 在 TiDB 集群中的应用
本节介绍 Promethues 在 TiDB 集群中的应用,主要包括通过 Prometheus PromQL 语言查看 TiDB 的监控,以及告警配置的讲解。
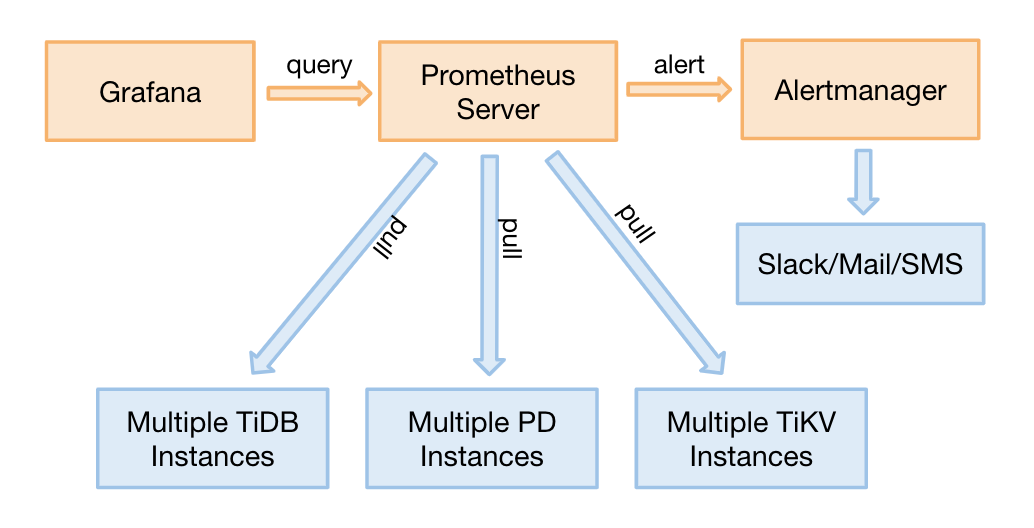
1. TiDB 集群中 Prometheus 的部署架构
TiDB 已经原生支持 Prometheus,在 2.1 之前的版本,TiDB 的监控信息是由各 TiDB 的各个组件主动上报给 pushgateway,再由 prometheus server 去 pushgateway 上主动抓取监控信息。从 2.1 版本开始,TiDB 暴露 Metrics 接口 ,由 prometheus server 主动抓取信息,这样的架构更符合 Prometheus 的设计思想,整个数据采集路径少了一层 pushgateway。数据采集完成后由 grafana 做报表展示,同时告警信息主动推送给 alertmanager,再由 altermanager 将告警推送到不同的消息渠道。
2. 通过 Prometheus PromQL 语言查看 TiDB 的监控
PromQL(Prometheus Query Language) 是 Promehteus 提供的函数查询语言,可以进行实时查询,也可以通过函数做聚合运算。本节介绍下如何通过 PromQL 对 TiDB 的监控信息进行查询。
(1) 数据类型
Promethes 中的数据类型分 4 类:
- Instant vector - 一个时间点的时序数据;
- Range vector - 一个时间段的时序数据;
- Scalar - 数字,浮点值;
- String - 字符串,当前还没有用。
(2) 通过 web UI 执行查询
下图是在 web UI (http://prometheus-server:9090/graph) 上执行 up{instance=”21.129.14.103:2998”} 表达式查询到的某个实例的存活状态。
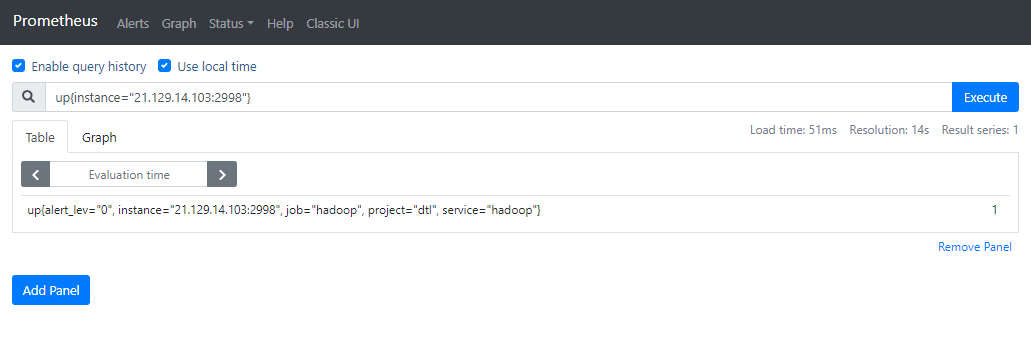
(3) 结果中各个字段的意义:
- up: 是一条具体的时序记录名字,同时 up 又是一条特殊的时序名称,他是 Prometheus 对每个监控对象自动生成的,指示该对象的起停状态,1 表示可连通,0 表示不可能连通(注意,0 不一定是服务挂了,也有可能是获取记录的时候超时了)。
- 表达式中的 instance, job, project, service, alert_lev 都是该条的记录的标签,相对于关系型数据库中的字段。其中 instance 和 job 是基于 prometheus.yaml 中的内容自动生成的,project, service, alert_lev 是用户自定义的标签。instance 一般是 prometheus 里的 target,但是也可以在标签里重写。
- 最后的 1 是这条记录在查询时的结果。
3. Instant vector 查询
下面列举下几种 Instant vector 查询的常见用法:
- 直接写时序名称,例如: server_query_total
- 在 {} 中加一些标签作为过滤条件,例如: server_query_total{job=”tikv”}
-
一个标签匹配多个值,例如: server_query_total{job=~”tikv tidb”} -
指定需要过滤掉值,例如: server_query_total{job!~”tikv pd”} - 匹配正则表达式,例如: up{tidb=~”.+”},可以匹配所以包含 tidb 的 up 时序数据
- 使用算术运算和比较运算过滤结果: tikv_engine_bytes_written{instance=”21.129.14.104:21910”}/1024/1024 > 500
4. Range vector 查询
Range vector 查询类似于 instance vector 查询,不同之处在于通过 [] 加上时间范围限制,时间单位可以设置为:
- s - seconds
- m - minutes
- h - hours
- d - days
- w - weeks
- y - years
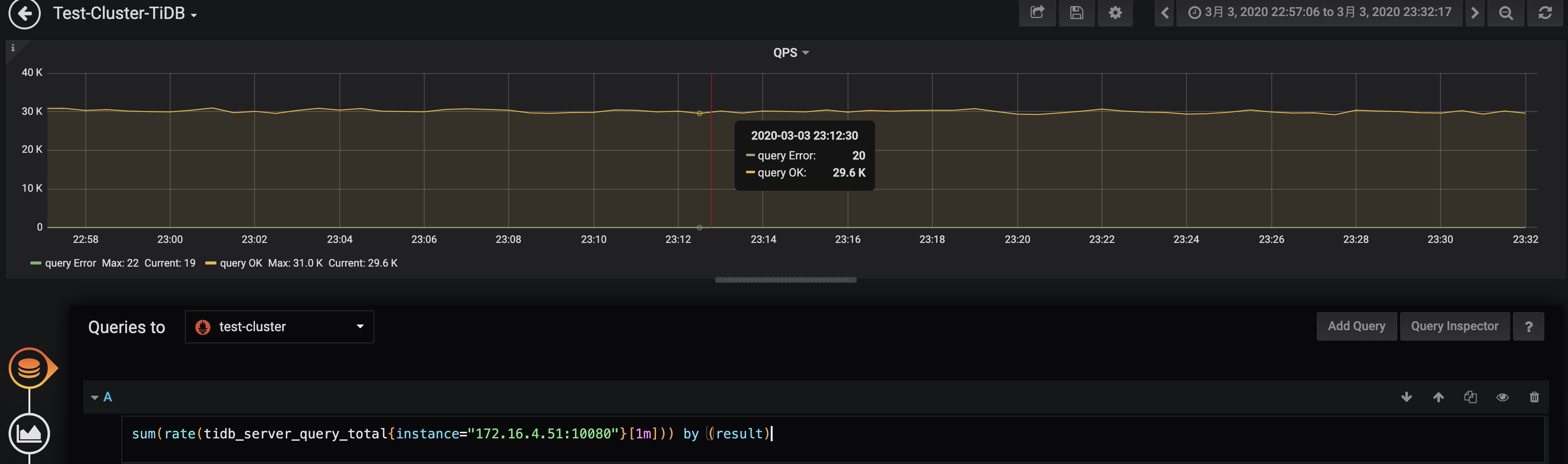
下面看看监控 TiDB QPS 的例子,展示的是 172.16.4.51:10080 这台 TiDB 实例的 QPS 情况:
5. offset 查询
通过 offset 能够查询过去某个时间点的监控结果,如下查询的是一天前 TiDB 的请求数总量:
sum((tidb_server_query_total{result=”OK”} offset 1d))
4.4.5 TiDB 监控中常用函数
本节结合实际例子,介绍下 TiDB 监控中经常用到的一些函数。
rate 和 irate
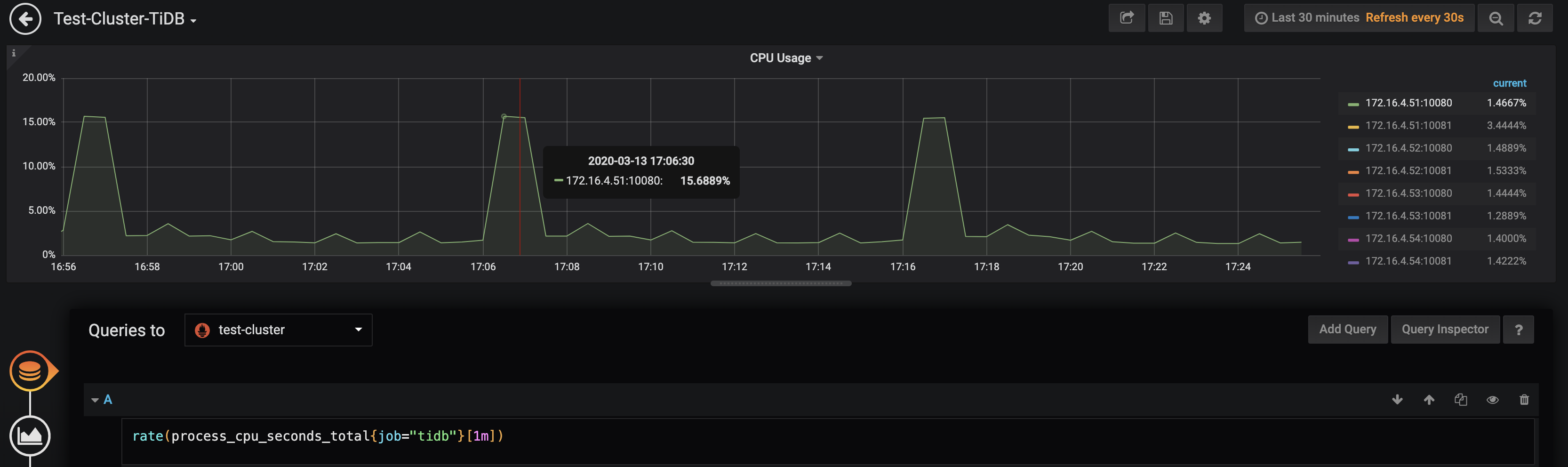
这两个函数一般作用于计数器 counter 类型的数据,这类数据会一直增加,使用这两个函数后,展示的是一定时间范围内的变化情况。但它俩的计算方式是有差异,irate() 是基于时间范围内连续的两个时间点,而 rate() 是基于时间范围内的所有时间点,所以 irate() 展示的数据更为精确些,做图毛刺也会更明显。下图展示的是 TiDB 集群中节点的 CPU 使用率的监控,对应的表达式是 rate(process_cpu_seconds_total{job=”tidb”}[1m])。
sum 和 avg
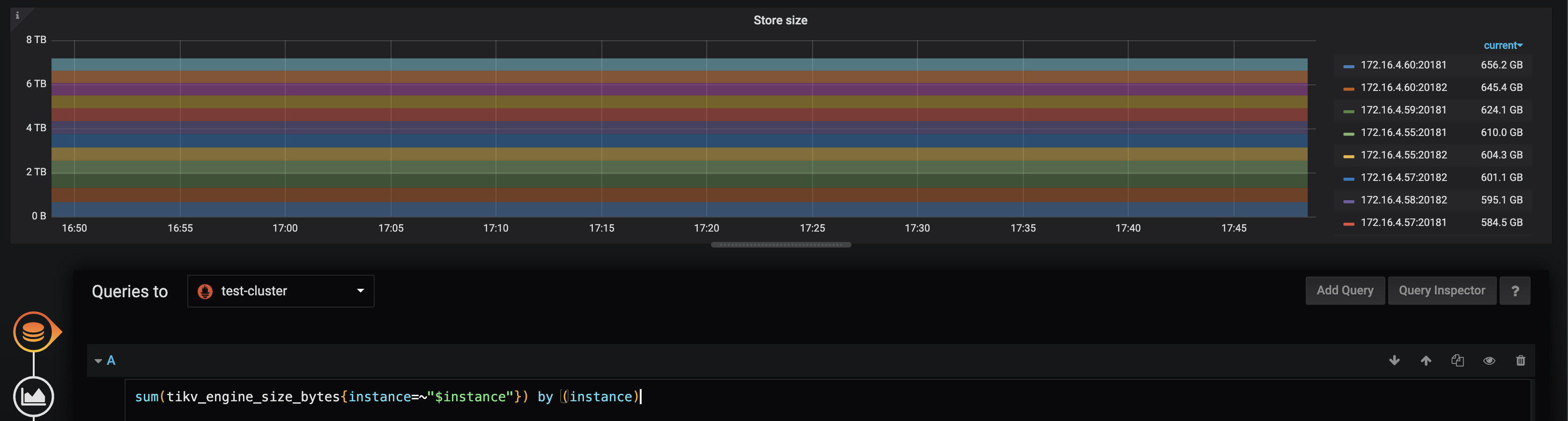
sum 是求和函数,avg 是求均值函数。表达式 sum(tikv_store_size_bytes{instance=~”$instance”}) by (instance) 查询的是各个 TiKV 实例的容量总和。
increase
increase 函数计算的是指定时间范围内的变化量,例如表达式 sum(increase(tidb_server_execute_error_total[1m])) by (type) 是以 type 为聚合条件,显示 1 分钟内 Failed Query OPM 总数

histogram_quantile
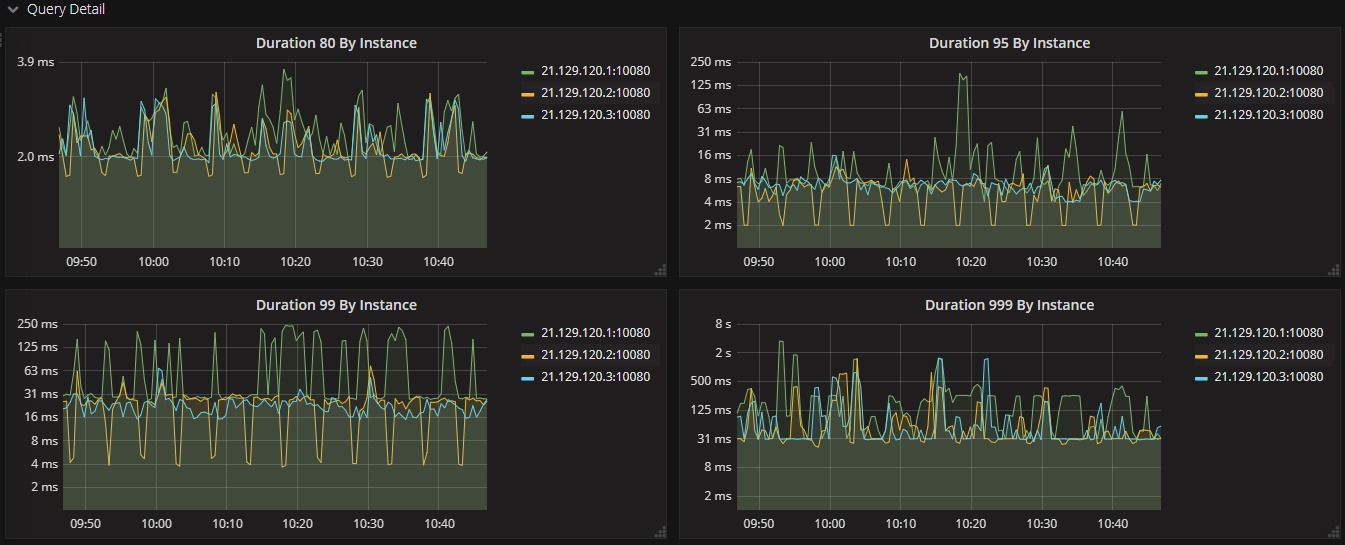
histogram_quantile 是累积直方图百分位函数,用法 histogram_quantile(φ float, b instant-vector),其中百分位 φ 是介于 0 和 1 之间的值。这个函数计算的结果是直方图中指定百分比的最大值,例如 0.95 的百分位的结果是 200,说明所有数据中,小于 200 的占总数据的比例为 95%。下面表达式是展示各个 tidb-server 请求的 99% 延迟情况。
histogram_quantile(0.99, sum(rate(tidb_server_handle_query_duration_seconds_bucket[1m])) by (le, instance))
4.4.6 通过配置 alertmanager 对 TiDB 故障进行报警
本节介绍下 TiDB 中是如何配置 Promethues 的报警的。如果是通过 tidb-ansible 方式部署的集群,Promethues 的报警配置文件对应的路径是 tidb-ansbile/roles/prometheus/files/tidb.rules.yml。
1. TiDB 告警级别
TiDB 组件的报警项,根据严重级别可分为三类,按照严重程度由高到低依次为:紧急级别、重要级别、警告级别。
紧急级别报警项
紧急级别的报警通常由于服务停止或节点故障导致,此时需要马上进行人工干预操作。告警规则里的标签 level: emergency。下面展示的是 TiDB_schema_error 的告警示例:TiDB 在一个 Lease 时间内没有重载到最新的 Schema 信息,导致 TiDB 无法继续对外提供服务,需要报警。该问题通常由于 TiKV Region 不可用或超时导致,需要看 TiKV 的监控指标定位问题,比如确认 TiKV 实例是否还存活着。
- alert: TiDB_schema_error
expr: increase(tidb_session_schema_lease_error_total{type="outdated"}[15m]) > 0
for: 1m
labels:
env: ENV_LABELS_ENV
level: emergency
expr: increase(tidb_session_schema_lease_error_total{type="outdated"}[15m]) > 0
annotations:
description: 'cluster: ENV_LABELS_ENV, instance: , values:'
value: ''
summary: TiDB schema error
重要级别报警项
对于重要级别的报警,需要密切关注异常的指标。告警规则里的标签 level: critical。下面示例展示的是 tidb-server 进程发生崩溃的时候进行报警。收到该报警的一般处理方式是收集 TiDB 的 panic 日志,定位 panic 的原因,比如是否是 tidb-server 实例 OOM 导致的问题。
- alert: TiDB_server_panic_total
expr: increase(tidb_server_panic_total[10m]) > 0
for: 1m
labels:
env: ENV_LABELS_ENV
level: critical
expr: increase(tidb_server_panic_total[10m]) > 0
annotations:
description: 'cluster: ENV_LABELS_ENV, instance: , values:'
value: ''
summary: TiDB server panic total
警告级别报警项
警告级别的报警是对某一问题或错误的提醒。告警规则里的标签 level: warning。下面展示的是对于 tidb-server 实例内存异常的报警,当 tidb-server 实例的内存占用大于 10GB 的时候进行报警。收到该报警的时候,需要注意是否有大查询在执行,比如大表的 Join 查询。
- alert: TiDB_memory_abnormal
expr: go_memstats_heap_inuse_bytes{job="tidb"} > 1e+10
for: 1m
labels:
env: ENV_LABELS_ENV
level: warning
expr: go_memstats_heap_inuse_bytes{job="tidb"} > 1e+10
annotations:
description: 'cluster: ENV_LABELS_ENV, instance: , values:'
value: ''
summary: TiDB heap memory usage is over 10 GB
更多关于 TiDB 报警规划,以及 TiDB 详细告警的处理方法,请参考 官网介绍 。
2. 为 TiDB 集群配置 alertmanager 告警路由
由于往外发送告警需要邮箱、短信、企业微信等外部消息通道打通,一般企业内部都有各自不同的安全要求和操作规范。另外像短信接口并不是统一标准的,大部分也不是原生支持 Prometheus 的,所以需要用户自己编写适配脚本,以 webhook 的方式与 alertmanger 进行适配。
建议使用 TiDB 时,用户自己创建一个独立的 alertmanager,用于接收来自不同 prometheus server 的告警,统一集中路由发送,既可以有效安全管理,也可以减少用户自己的部署操作。如果用户采用的是 tidb-ansible 方式部署的 TiDB 集群,alertmanager 的配置文件位于 tidb-ansible/conf/alertmanager.yml。
告警路由配置
routes:
- match:
env: test-cluster
level: emergency
receiver: tidb-emergency
group_by: [alertname, cluster, service]
下面简单解释下各个字段的含义:
- match 是一条路由规划。
- env 和 level 是从 Prometheus 发送过来的记录所携带的标签,如果能够匹配该标签,则符合当前这条路由规则。
- receiver 表示接收人,和后面接收部分的 name 一致。
- group_by 里面的内容是分组聚合的标签。
告警接收配置
receivers:
- name: 'tidb-emergency'
webhook_configs:
- url: 'xxxx'
wechat_configs:
- corp_id: 'xxxxx'
to_party: 'xxx'
agent_id: 'xxxx'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
api_secret: 'xxxxxx'
- name:和上面路由规则的 receiver 对应。
- webhook_configs:以 webhook 的方式发送。
- wechat_configs:以企业微信的方式发送,具体要求参考 企业微信 文档;
- 由于默认的告警发送的内容过多,包含注释等信息,影响可读性。建议用户自己写 webhook 的方式发送告警。