tidb-in-action
第1章 适用场景介绍
谈到场景我们不禁会想到各种各样的案例,单纯只是罗列案例无疑会浪费大量篇幅,读者也未必会找到一条清晰的脉络来回答一个问题“TiDB是否适合我现在的工程环境?”。我们不妨换个角度,所谓适用场景,首先要明确解决什么问题,然后考察产品的哪些特性有利于解决问题,对比类似方案的优缺点,最后通过阅读实际案例增强感性认知。通过前述过程,在面对具体环境时,就可以快速判断产品是否适用,保证选型的正确性。在本节中我们会给出常见的场景描述和经典案例,让读者对 TiDB 的场景有更具体的认识。
1. TiDB 要解决什么问题
在 20 年前,大家对数据库的认知可能比较单一,大致的概念是“支持 SQL 的数据存储软件产品”,基于等同于关系型数据库(RDBMS)。单机关系型数据库如日中天,掩盖了其他类型数据库的光芒。随着互联网的发展,开始认识到传统单机关系型数据库的局限。数据的概念被泛化,如今支持数据存储和查询的软件系统都被叫做数据库,于是出现了文档数据库、时序数据库、分布式数据库、KV 数据库等等。简而言之,都是为了满足传统单机数据库扩展性的不足。很多新的数据库支持横向扩展的同时放弃了 SQL 语言和事务支持,这类数据库被称为 NoSQL。大部分 NoSQL 产品牺牲强一致性换取扩展性,开发者要自己实现业务出错时的补偿机制。没有标准的数据操作规范,程序员需要面对各种数据操作接口,增加了出错的概率。最近几年,人们开始意识到了标准的数据操作对于开发和维护的意义。简单来讲,数据库的发展趋势就是:SQL -> NoSQL ->No only SQL。
回归并非回到原点,而是螺旋上升。大家期待一种数据库,既兼容SQL,又可以横向扩展,并支持事务,这也是 NewSQL 的定义。TiDB 正是一款 NewSQL 数据库产品。如果你现在正在使用 MySQL 数据库,面对无法承载的海量业务又不想让分库分表折磨,TiDB 无疑是目前最好的选择,这也是 TiDB 最为经典的场景。泛化一点,需要在数据层面横向扩展又需要兼容 SQL 和事务 ACID 特点的技术团队都可以尝试 TiDB。
在进行 TiDB 产品适用场景的正式介绍之前,可以站在使用者的角度,来观察 TiDB 的最为突出的特质:
- 架构经过重新设计,可以横向扩展的 MySQL。
- Raft 多数派一致性协议实现数据的高可用和存储的灵活性。
- 不同计算场景的需求可以灵活地访问共存的行式和列式数据。
- 计算存储分离的分布式架构易于与云的弹性特质结合。
2.适用场景
高并发 OLTP
MySQL 是第一个广泛使用的开源关系型数据库,也是国内互联网业务数据库的事实标准。面对终端用户的迅猛增长,MySQL 数据库的架构方案很快就会面临承载能力上限。在 NewSQL 还没有出现前,MySQL 遭遇业务迅速增长造成的瓶颈时,数据库架构的演化方向通常会选用分库分表方案。
分库分表将高吞吐的大表按主键值的 Hash 值进行切分(称为 Sharding),表上数据的分发、路由引入中间件进行处理。自下而上分为三层,分别 DB 层、中间层、应用层。分库分表方案部分解决了业务扩展的问题,但对开发和运维造成巨大的压力。业务需要提供切分维度,不支持在线 DDL 操作,不能跨维度 Join / 聚合 / 子查询,不支持分布式事务,无法实现多维度的业务需求。业务程序从单机数据库迁移到分库分表方案时,通常要完成大量的开发适配改造。不能在线进行扩缩容,不能实现一致性的备份还原,难以实现异地容灾等。
TiDB 最初的目标使用场景就是通过计算存储分层的分布式设计实现单机 MySQL 性能的突破。TiDB 之于分库分表方案是一种颠覆,分布式架构优雅地实现了水平扩展,解决了诸多的开发限制。计算层关系型二维表与存储层 KV 键值对两种模式的转换关系,支持多维度的业务需求和复杂 SQL 查询,支持在线 DDL。Percolator 事务模型能保证 ACID 。基于 Region 的 Multi-Raft 设计,支持以较小的成本进行在线扩缩容,支持无人工介入的高可用等。
| 类型 | 分库分表 | TiDB |
|---|---|---|
| 强一致的分布式事务 | 不支持 | 支持 |
| 水平扩展 | 不支持 | 支持 |
| 复杂查询 (JOIN/ GROUP BY/…) | 不支持 | 支持 |
| 无人工介入的高可用 | 不支持 | 支持 |
| 业务兼容性 | 低 | 高 |
| 多维度支持 | 不友好 | 友好 |
| 全局 ID 支持 | 不友好 | 友好 |
| 机器容量 | 很浪费 | 随需扩容 |
TiDB 兼容 MySQL 的开发生态,基于 MySQL 的业务只需要修改数据源连接 TiDB 就能运行,节点数可横向扩展适配业务变化。在 TiDB 4.0 中,弹性调度特性能根据现有的热点统计,利用 K8s 容器编排平台上灵活的调度能力,自动化地扩展 TiKV Pod 并迁移热点 Region,实现对前台业务负载变化的快速响应。
案例参考
- TiDB 在知乎万亿量级业务数据下的实践和挑战
https://pingcap.com/cases-cn/user-case-zhihu/
- TiDB at 丰巢:尝鲜分布式数据库
https://pingcap.com/cases-cn/user-case-fengchao/
实时分析
传统的数据架构设计中,每个数据库都有一个明显的角色身份,比如业务系统库,经营分析库,报表库,数据仓库等。使用 ETL 工具按照时间和数据获取策略将交易数据抽取到数据分析平台,满足业务的分析需求。受制于数据抽取方式的时间策略和分析平台的性能,业务部门最常抱怨的莫过于分析时效性,实时分析的概念应运而生。在实时分析领域,离线和在线的边界越来越模糊,一切数据皆服务化,一切分析皆在线化。数据的实时分析结果直接服务于业务,这对系统处理延时提出了新的挑战。
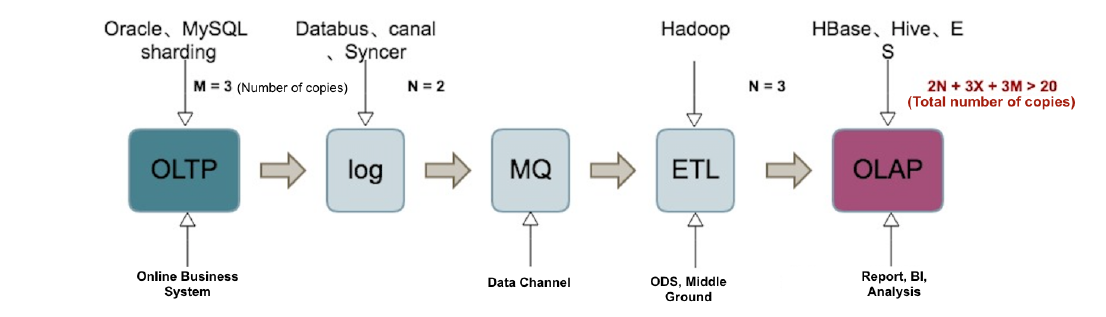
在 TiDB 4.0 版本之前,很难在一个集群内既支持实时分析处理,又要支持高并发的在线交易。3.0 版本中的TiSpark 组件, 将 Spark 的计算能力嫁接到 TiDB 的存储引擎 TiKV 之上。由于 Spark 的计算模型重且资源消耗高,在没有资源隔离支持的情况下,通常会将存储引擎的处理能力消耗殆尽,实时分析和交易处理成为“鱼和熊掌不可兼得”。
在 TiDB 4.0 版本中,引入列存引擎 TiFlash,既加速了分析运算,又解决了资源隔离的问题。通过 Raft learner 机制,将行存数据复制出列存数据,使用 Engine tag 实现访问资源的物理隔离。两种不同资源需求的场景实现共存,实时分析使用列存引擎 TiFlash ,交易处理使用行存引擎 TiKV。列存引擎 TiFlash 组件的加入,补全 TiDB 的 HATP 版图。
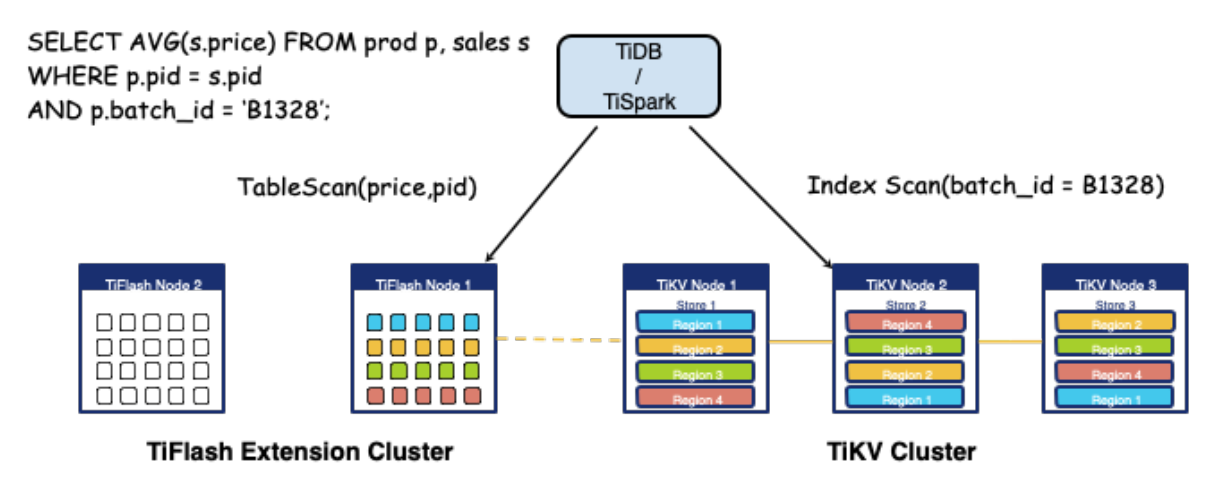
对于业务更具价值的是,Raft learner 机制能将行存引擎上最为新鲜的业务数据复制到 TiFlash 中,实现业务数据的实时分析,分析的结果可以回写到行存引擎,为实时数据服务提供更多的想象空间。熟悉 Oracle 的读者,对于报表系统使用 DataGuard 备库,计算结果写回主库的架构设计应该不陌生。TiDB HTAP 架构的优势在于,在一套集群内通过扩展存储引擎组件的方式实现计算访问的灵活性,列式的存储不仅能够极大地加速分析场景的计算,同时交易场景可以利用列存实现类似索引的效果。在表级别实现灵活的配置方式,也免去整个过程中的人工介入减少大量的维护成本。
案例参考
- TiDB / TiSpark 在易果集团实时数仓中的创新实践
https://pingcap.com/cases-cn/user-case-yiguo/
多活场景
多个数据中心内部署业务系统组件,如数据库服务器、应用服务器,并组成一个有机的整体,用户能够接入任意一个数据中心的业务系统实现多活访问,能有效提高系统健壮性和业务流量承载能力。
多活场景最主要的难点在于业务系统需要在同一份数据上提供数据服务。假设多活数据中心共有 A、B、C 三个站点,结合业务对于数据一致性的要求,需要保证在 A 站点发生故障后,业务系统此前发生的操作,在另外两个站点上也能访问到。常见的多活基础架构方式有:
- 数据库集群结合裸光纤互连的存储容灾复制方案,比如 Oracle Extended RAC。
- 按站点进行应用数模设计结合数据复制的,比如 A 站点的记录号为奇数,B 站点的记录号为偶数,利用序列的步长避免记录操作冲突,同时使用 Oracle GoldenGate 进行双向复制。
- 在应用层设计共享中心和业务中心,终端用户绑定业务中心属主,当用户访问非属主业务中心时,共享中心自动实现用户的漫游和数据跨中心的数据访问。
以上的多活设计方式中,如果优先保证一致性就会影响性能,如果优先满足性能就需要在一致性上做妥协。
在 TiDB 的多活场景设计中,根据各个分布式组件的高可用机制实现多活部署。TiDB Server 属于无状态应用,类似 Web 服务器,在多个站点部署结合负载均衡设备实现高可用和多活访问。TiKV Server 和 PD Server 基于 Raft 多数派一致性协议实现高可用。TiKV Server 以 Region 为单位,按指定的数据副本数进行存储,属于 Multi-Raft 设计。在高可用设计上还引入 DC / Zone / Rack / Host 的四层标签体系和 Raft Leader 的 Reject 排斥策略,能灵活地指定在多个站点的数据副本分布和 IO 的流量导向。数据写入时,只需要在延时较低的站点内写入足够的数据副本数量就可以返回写入成功,同时满足性能和数据一致性要求。PD Server 属于单 Raft 组设计,节点数等于数据副本数,在多个站点均衡配置 3 个或者更多节点。
TiDB 的多活架构设计,不需要在应用层数模做特殊设计,实现原生业务的多活。Raft 的多数派一致性设计,既降低了多活的网络要求,又满足了数据的高可用要求。同时整个多活体制的高可用机制,均由底层体制自动实现,不需要人工介入和额外的操作流程。TiDB 4.0 的 Follower Read 特性,能实现同站点读取操作的亲和性,有效提高存储层的数据吞吐能力并降低跨站点的网络流量,进一步降低了网络成本。
- TiDB 在银行核心金融领域的研究与两地三中心实践
https://pingcap.com/cases-cn/user-case-beijing-bank/
- 微众银行数据库架构演进及 TiDB 实践经验
https://pingcap.com/cases-cn/user-case-webank/
3.经典案例
经过几百个用户实际使用,TiDB 产品积累了大量的案例。在这些案例中,也许读者会找到自己场景的影子,或者案例本身就是你面对场景的 TiDB 解决方案。欢迎访问以下链接阅读用户案例。
用户案例汇总链接(https://pingcap.com/cases-cn/)