tidb-in-action
相对于从其它数据库向 TiDB 进行单次迁移切换,TiDB 到 TiDB 的数据复制体系一般是长期的高可用容灾场景,适用于多机房、多数据中心等环境,需要更加稳定可靠。建议增加服务管理和数据比对校验等辅助机制。
DataX 工具实现跨 TiDB 集群的增量数据复制,是在 TiDB 4.0 的 CDC 工具正式发布前比较成熟的一项选择,有利于在数据中心内统一同异构平台的数据传输工具。
下面会以双 TiDB 集群互为主备的场景为案例进行操作讲解。从设计上既满足了传统数据库运维的要求,生产数据库拥有容灾备库提高系统健壮性,又使得服务器硬件等资源得到了更充分的利用。
方案设计如图所示
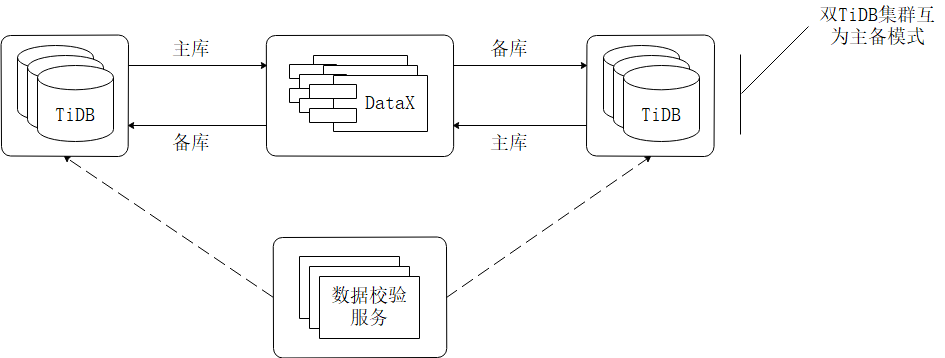
具体操作步骤:
第一步:部署DataX
下载
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
解压
tar -zxvf datax.tar.gz
自检
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
第二步:编辑同步Job
vi increase.json
{
"job": {
"setting": {
"speed": {
"channel": 128 #根据业务情况调整Channel数
}
},
"content": [{
"reader": {
"name": "tidbreader",
"parameter": {
"username": "${srcUserName}",
"password": "${srcPassword}",
"column": ["*"],
"connection": [{
"table": ["${tableName}"],
"jdbcUrl": ["${srcUrl}"]
}],
"where": "updateTime >= '${syncTime}'"
}
},
"writer": {
"name": "tidbwriter",
"parameter": {
"username": "${desUserName}",
"password": "${desPassword}",
"writeMode": "replace",
"column": ["*"],
"connection": [{
"jdbcUrl": "${desUrl}",
"table": ["${tableName}"]
}],
"preSql": [
"replace into t_sync_record(table_name,start_date,end_date) values('@table',now(),null)"],
"postSql": [
"update t_sync_record set end_date=now() where table_name='@table' " ]
}
}
}]
}
}
第三步:编写运行DataX Job的Shell执行脚本
vi datax_excute_job.sh
#!/bin/bash
source /etc/profile
srcUrl="Reader SourceTiDB 地址"
srcUserName="账号"
srcPassword="密码"
desUrl="Writer DestTiDB 地址"
desUserName="账号"
desPassword="密码"
#同步开始时间
defaultsyncUpdateTime="2020-03-03 18:00:00.000"
#同步周期(秒)
sleepTime="N"
tableName="Table1,Table2,..."
#循环次数标识,-1为一直循环,其他按输入次数循环,可根据需求自定义传参。
flg=-1
while [ "$flg" -gt 0 -o "$flg" -eq -1 ]
do
#更新时间设置为上次循序执行的时间
if [ "" = "$preRunTime" ]; then
syncTime=$defaultsyncUpdateTime
else
syncTime=$preRunTime
fi
#记录下本次循环执行时间,供下次循环使用
preRunTime=$(date -d +"%Y-%m-%d %T")".000";
echo $syncTime
echo $preRunTime
echo $flg
python {YOUR_DATAX_HOME}/bin/datax.py -p "-DsyncTime='${syncTime}' -DtableName='${tableName}' -DsrcUrl='${srcUrl}' -DsrcUserName='${srcUserName}' -DsrcPassword='${srcPassword}' -DdesUrl='${desUrl}' -DdesUserName='${desUserName}' -DdesPassword='${desPassword}'" {YOUR_DATAX_HOME}/job/increase.json
if [ -1 -lt "$flg" ]; then
let "flg-=1"
fi
sleep $sleepTime
done
第四步:执行Shell脚本
chmod +x datax_excute_job.sh
nohup ./datax_excute_job.sh > log.file 2>&1 &
DataX Job 的 Shell 执行脚本可以注册在 Supervisor 等服务工具中管理。当双 TiDB 集群需要进行主备切换时,可以做到任务随时启停,正反向同步随时切换。
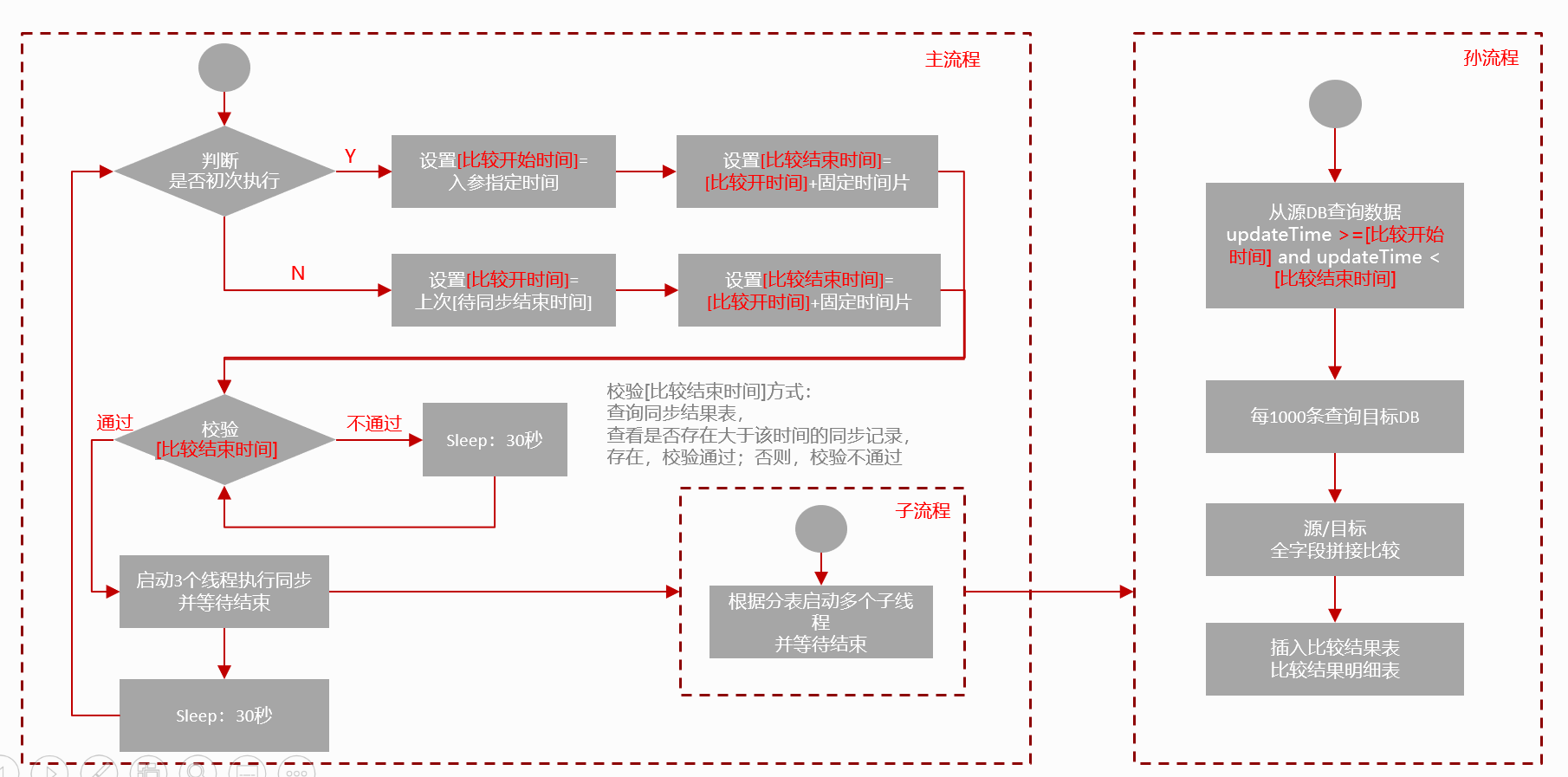
第五步:数据校验服务
按自定义时间跨度查询两个 TiDB 的数据,设置流式读取两个 TiDB 中表数据,转成字符串进行对比,更高效。在比对过程中,为了提高比对效率,如果发现不一致,记录哪张表的哪个时间片有不一致即可,不需要运算定位到具体某一行。对于发现不一致的记录可以发送报警,人工介入处理,也可以调动同步脚本,重新同步一次,可根据自己的业务灵活选择。
简单的数据校验流程可以参考下图。
用DataX 进行双 TiDB 集群间的数据同步不一定是最好的,但每个方案都有其特定存在的场景和意义。如果双集群间广域网链路质量不太稳定,又或者有特殊的定制需求等原因时,可以考虑本方案。