tidb-in-action
6.3 TiDB + TiSpark 跑批最佳实践
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。在借助 Spark 平台在计算及生态等方面优势的同时也融合了 TiKV 分布式集群的优势,为大数据环境下的批量任务提供了一种解决方案。在本节将介绍如何在已有的 TiDB 集群基础上引入 TiSpark 进行批量任务开发。本节假设你对 Spark 有基本认知。你可以参阅 Apache Spark 官网 了解 Spark 相关信息。
6.3.1 TiSpark 概述
TiSpark 是将 Spark SQL 直接运行在 TiDB 存储引擎 TiKV 上的 OLAP 解决方案。TiSpark 架构图如下:
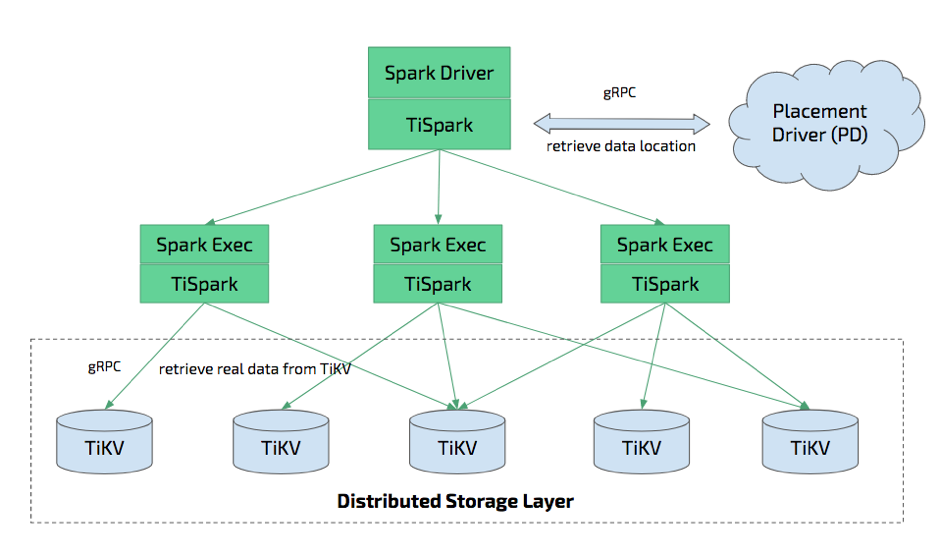
-
TiSpark 深度整合了 Spark Catalyst 引擎, 可以对计算提供精确的控制,使 Spark 能够高效的读取 TiKV 中的数据,提供索引支持以实现高速的点查;
-
通过多种计算下推减少 Spark SQL 需要处理的数据大小,以加速查询;利用 TiDB 内建的统计信息选择更优的查询计划。
-
从数据集群的角度看,TiSpark+TiDB 可以让用户无需进行脆弱和难以维护的 ETL,直接在同一个平台进行事务和分析两种工作,简化了系统架构和运维。
-
除此之外,用户借助 TiSpark 项目可以在 TiDB 上使用 Spark 生态圈提供的多种工具进行数据处理。例如使用 TiSpark 进行数据分析和 ETL;使用 TiKV 作为机器学习的数据源;借助调度系统产生定时报表等等。
6.3.2 环境准备
(1) TiSpark 依赖包
当前,TiSpark 2.1.8 是最新的稳定版本,官方强烈建议使用。它与 Spark 2.3.0+ 和 Spark 2.4.0+ 兼容。它还与 TiDB-2.x 和 TiDB-3.x 兼容。可以前往 TiSpark 在 GitHub 上的首页查看更详细的版本兼容情况并下载。
(2) Spark
根据现有 TiDB 版本确定兼容的 TiSpark 依赖以后,便可以从 Spark 官网下载支持的版本,这里推荐下载自带 Hadoop 环境的预编译版。
(3) JDK
TiSpark 需要 JDK 1.8+ 以及 Scala 2.11(Spark2.0+ 默认 Scala 版本)。
6.3.3 TiSpark 集群部署配置
TiSpark 可以在 YARN,Mesos,Standalone 等任意 Spark 模式下运行。这里使用 Saprk Standalone 方式部署。关于 Saprk Standalone 的具体配置方式请参考官方说明,下面给出的是与 TiSpark 相关的配置范例。
(1) spark-env.sh 配置
SPARK_EXECUTOR_MEMORY=10g
SPARK_EXECUTOR_CORES=5
SPARK_WORKER_MEMORY=40g
SPARK_WORKER_CORES=20
(2) spark-defaults.conf 配置
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses 127.0.0.1:2379
其中 PD 格式为 地址:端口号,多个 PD 使用逗号间隔。
(3) 部署 TiSpark
将 TiSpark 组件部署到 Spark 集群有两种方式,如果不想重启现有集群,可以使用 Spark 的 –jars 参数将 TiSpark 作为依赖引入:
sh spark-shell –jars $TISPARK_FOLDER/tispark-${name_with_version}.jar
如果想将 TiSpark 作为默认组件部署,只需要将 TiSpark 的 jar 包放进 Spark 集群每个节点的 jars 路径并重启 Spark 集群:
${SPARK_HOME}/jars
(4) 启动 TiSpark 集群
在选中的 Spark Master 节点执行如下命令:
cd ${SPARK_HOME}
./sbin/start-all.sh
命令执行以后,控制台会输出 master 和 slave 的启动信息并指出相应 log 文件。检查 log 文件确认集群各个节点是否启动成功。可以打开 http://spark-master-hostname:8080 查看集群信息(Spark-Master 默认的 web 端口号)。
6.3.4 使用范例
假设你已经按照上面的步骤成功部署并启动了 TiSpark 集群,下面分别介绍使用 Spark-Shell 和 Spark-Submit 两种方式来作 OLAP 分析。
(1) Spark-Shell
如果你的 TiSpark 版本是 2.0 以上,那么在 Spark-Shell 中你可以直接调用 Spark SQL 与 TiDB 数据库交互:
spark.sql("use test")
spark.sql("select count(*) from user").show
TiSpark 版本在 2.0 以前的需要在之前执行如下命令:
import org.apache.spark.sql.TiContext
val ti = new TiContext(spark, List("127.0.0.1:2379")
ti.tidbMapDatabase("test")
之后便可以像上面那样调用 Spark SQL,不过建议尽量使用 2.0 以上版本的 TiSpark。
(2) Spark-Submit
在实际开发中,Spark-Shell 多用于测试,更多时候需要将代码打包后使用 Spark-Submit 命令提交到 TiSpark 集群。
如果你的工程是采用 Maven 构建的,需要在 POM 文件中引入 Spark 及 TiSpark 依赖,由于这些依赖在 Spark 集群上已经存在,需要将他们的依赖范围设置为 Provided。
<dependencies>
<dependency>
<groupId>com.pingcap.tispark</groupId>
<artifactId>tispark-core</artifactId>
<version>2.1.8-spark_${spark.version}</version>
<scope>provided<scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided<scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided<scope>
</dependency>
</dependencies>
配置好必要的依赖以后,便可以使用如下代码初始化一个 SparkSession 对象,Spark 提供了面向多种语言的 API,如 Scala、Python、Java 等,本节均以 Java 为例。
SparkSession sc = SparkSession
.builder()
.appName("TiSpark example")
.master("local")
.config("spark.sql.extensions","org.apache.spark.sql.TiExtensions")
.config("spark.tispark.pd.addresses", "127.0.0.1:2379")
.getOrCreate();
上面的代码支持你在本地调试你的 TiSpark 程序,如果你要打包到 Spark 集群运行,那么指定 master 和 TiSpark 的两个配置项都是不需要的。 接下来我们结合一个常见的场景展示一个批量任务案例:每天有一些交易文件需要落表,它包含交易双方和金额信息,之后需要基于该表进行分析。在这个案例中可以拆解出两个最基本的批量任务。
一个任务负责解析每天的文件并将数据写入目标表,目前 TiSpark 不支持直接将数据写入 TiDB,但可以采用 Spark 原生 JDBC 方式写入,Java 案例代码如下:
sc.read().schema(getStructType())
.option("delimiter",true)
.option("header",true)
.csv(filePath)
.withColumn("input_time", functions.current_timestamp())
.repartition(100)
.write().mode(SaveMode.Append)
.jdbc(url,tableName,connProperties);
public StructType getStructType(){
List<StructField> fields=new ArrayList<>();
StructField transferAccount = DataTypes.createStructField("transferAccount",DataTypes.StringType,false);
StructField receiveAccount = DataTypes.createStructField("receiveAccount",DataTypes.StringType,false);
StructField amount = DataTypes.createStructField("amount",DataTypes.createDecimalType(10,2),false);
fields.add(transferAccount);
fields.add(receiveAccount);
fields.add(amount);
return DataTypes.createStructType(fields);
}
在这段代码中为顺利解析文件而定义了被解析文件的格式和字段属性,随后为数据集添加了一个标志入库时间的列,最后将数据集以追加的方式写入到目标表。 关于写入 TiDB,有以下几点需要注意:
- 为了获得更好的写入效率并充分利用 Spark 集群资源,在写入之前最好使用 repartition 算子对数据进行再分区, 充分发挥 Spark 集群的计算能力,具体数值要根据任务数据量和集群资源来决定。
- 要想让数据进行批量写入,TiDB 连接串中需要跟上 rewriteBatchedStatements 参数并将其设置为 True,然后通过 JDBCOptions.JDBC_BATCH_INSERT_SIZE 参数去控制批量写入的大小,官方推荐的大小为 150 。
- 对于大量数据写入,推荐将事务隔离级别参数 isolationLevel 设置为 NONE。
另一个任务从数据库读取数据进行分析,一段简单的 Java 分析代码如下:
sc.sqlContext()
.udf()
.register("convert",newConvertUDF(),DataTypes.createDecimalType(10,2));
sc.sql("select transferAccount,receiveAccount,convert(amount) from tableName where receiveAccount='0001'");
上面的代码从表中筛选出账户号为 0001 的所有入账信息,其中 convert 是一个提供单位转换功能的自定义 UDF 函数,他在被注册到 Job 后可以直接在 Spark SQL 中使用。 Spark SQL 支持各种自定义 UDF 或 UDAF 函数,合理利用这个特性可以使你的 SQL 更加强大。TiSpark 支持常见的各种 SQL 语法,如连接和子查询,不过目前 TiSpark 暂时不支持 update 和 delete 的操作,后续会考虑支持这两个操作。
在开发完毕并将代码打包后,使用 Spark-Submit 命令将任务提交到 Spark 集群:
cd ${SPARK_HOME}
./bin/spark-submit \
--class Analyze \
--master spark://127.0.0.1:7077 \
/home/tispark/TiSparkExample.jar
关于 Spark-Submit 命令的更多参数,请参考 Spark 官网。
6.3.5 小结
本节介绍了如何在现有 TiDB 集群基础上部署和配置 TiSpark 集群,并通过一些简单案例展示了如何使用 TiSpark 组件进行批量任务开发。你应该发现了,使用 TiSpark 开发与原生 Spark 相比没有什么差别,如果你本就熟悉 Spark 的话会很快上手,这正如 TiSpark 官方所说的那样,TiSpark 只是 Spark 之上的一个薄层。
如果你想使用 TiSpark 支撑批量任务的话,目前为止还是不够完善的,至少还有两个方面的问题需要解决。
首先在案例中是通过手动执行 Spark-Submit 命令提交任务的,这种方式只能用于调试不能用于生产,它也无法帮助你管理和监控批量任务,你需要引入类似 Oozie 和 Azkaban 这样的批量工作流任务调度器,他们能帮助你管理批量任务并轻松做到定时运行或是组合多个任务这样的高级功能。如果有条件可以选择自主开发,毕竟适合自己的才是最好的。
另一个问题是,使用 Spark API 进行开发虽然简单但也无法适应各种类型的批量任务,而 Spark 任务参数众多,有时需要根据每个任务的具体情况随时做出调整,这就使得你必须有某种参数解析机制来保证在批量任务运行时动态调整。所以你还需要在 Spark API 基础上设计一套适合你业务需求的批量任务代码规范,这样你就能保证批量任务的规范性和可靠性,同时也能减少冗余代码达到简化开发的目的。