tidb-in-action
7.4 TiDB OOM 的常见原因
日常 TiDB 运维中,会遇到组件 OOM 的问题,通常出现在 TiDB-Server 和 TiKV-Server,分别来看一下出现的常见原因以及处理建议。
7.4.1 TiDB-Server
1. 如何快速确认 TiDB-Server 出现了 OOM
- 客户端收到 tidb-server 报错 “ERROR 2013 (HY000): Lost connection to MySQL server during query”
- TiDB grafana 面板中 Server 的 Heap Memory Usage 项,出现一次或者多次内存上涨并突然下跌到底的情况
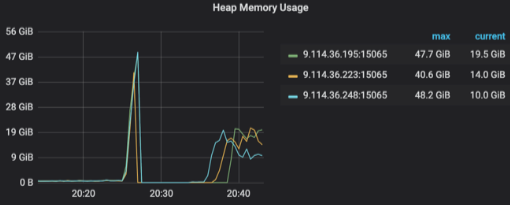
- 查看 TiDB service 的启动时间
$ systemctl status tidb-4000.service ●tidb-4000.service - tidb-4000 service Loaded: loaded (/etc/systemd/system/tidb-4000.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2020-02-21 12:30:04 CST; 5 min ago - 查看日志
- /var/log/message&kern,是否出现 “out of memory”字样,和 “TiDB service was killed”
- tidb.log 中可以 grep 到事故发生后附近时间的 “Welcome to TiDB” 的日志(即 tidb-server 发生重启)
- tidb_stderr.log 中能 grep 到 “fatal error: runtime: out of memory” 或 “cannot allocate memory”
2. TiDB-Server 出现 OOM 的常见原因
导致 TiDB oom 的本质原因是 TiDB 现有的内存小于 TiDB 要使用的内存。
- 复杂查询
SQL 执行计划中的 root 任务占比过高,TiDB-Server 需要缓存大量数据。比如执行计划中使用了 hash join、过多的子查询、Update&Delete 涉及数据量过大等等。
- 机器内存不足,机器上部署的其他应用占用了较多内存,如 Prometheus
- 活跃线程数过多,导致内存用尽
- mydumper导数据时,并发量太大
3. 如何缓解 TiDB-Server OOM 问题
- 参照本书 “快速定位慢 SQL” 的章节,通过添加索引或者优化 SQL 语句来解决
- 配合 tidb_mem_quota_query 限制单个 Query 的内存消耗,默认值为 32GB
global: mem-quota-query: 209715200 //举个例子:将阈值设置为 200MB oom-action: "cancel" //超过阈值的 SQL 自动杀掉 - max_execution_time 限制单个 SQL 执行时间
set @@GLOBAL.max_execution_time=10000; //限制 SQL 执行最长时间为 10s - 开启 SWAP,可以缓解由于大查询使用内存过多而造成的 OOM 问题。
但该方法会在内存空间不足时,由于存在 IO 开销,因此大查询性能造成一定影响。性能回退程度受剩余内存量、读写盘速度影响。 - 目前 4.0 版本已经支持 oom-use-tmp-storage 功能
设置为 `true` 可以使单条 SQL 内存使用在超出 `mem-quota-query` 时为某些算子启用临时磁盘 - 增大 TiDB 现有内存
TiDB 实例默认使用服务器全部内存的,提升物理服务器内存在真实场景中并不现实。但当前市场上服务器多 NUMA 架构,TiDB 使用建议中存在着 NUMA 绑核的机制。 如果在做绑核动作时,如果使用了 membind 参数(Only allocate memory from nodes. Allocation will fail when there is not enough memory available on these nodes. nodes may be specified as noted above)绑定到 NUMA NODE上,则默认只能分配该 NUMA NODES 上的内存,而非全部; 推荐使用 preferred 参数(Only allocate memory from nodes. Allocation will fail when there is not enough memory available on these nodes. nodes may be specified as noted above)进行绑定,其含义为首先使用分配的 NUMA NODE 的内存资源,不足时会使用其他节点的内存。 这样可以提高 TiDB 使用内存的水位。 sudo -s numactl --preferred=node - 减少 TiDB 使用内存。
1)优化单一大 SQL
当出现 TiDB OOM 时 ,去查看对应的 tidb_slow_query.log 通过 Query_time 和 Mem_max 值定位使用内存过多的慢 SQL 。
如果是查询 SQL 可通过其执行计划定位,是否存在着以下动作:
全表扫描 table scan 优化思路:考虑新建索引。
hash join 优化思路:注意表之间的排列顺序,让筛选性好的表优先 join ;考虑使用 index loop join 代替。
如果是 delete 语句,可以考虑使用 tidb_batch_delete 方式,或业务上分片方式,达到少量多次的效果。
2)横向扩容 TiDB
面对没有单一大 SQL ,而是并发较高的场景,可以选择横向扩展 TiDB 节点来缓解单一 TiDB 实例的压力,从而起到缓解 oom 的作用。
7.4.2 TiKV-Server
TiKV-Server OOM 的常见场景有如下几种,不同场景的处理建议也有不同。
1. block-cache 配置过大
在 TiKV grafana 选中对应的 instance 之后查看 RocksDB 的 block cache size 监控来确认是否是该问题。同时检查 参数是否设置合理,默认情况下 TiKV 的 block-cache 设置为机器总内存的 45%,在 container 部署的时候需要显式指定该参数,因为 TiKV 获取的是物理机的内存,可能会超出 container 的内存限制。
[storage.block-cache]
capacity = "30GB"
处理建议:
- 适当增大机器内存
- 适当减小 block-cache
2. coprocessor 收到大量大查询,需要返回大量的数据
gRPC 发送速度跟不上 coprocessor 往外吐数据的速度导致 OOM。可以通过检查 [tikv-detail]->[Coprocessor Overview]->[Total Response Size] 是否超过 network outbound 流量来确认是否属于这种情况。
处理建议:
- 使用万兆网卡,提高数据传输速度
- 参照本书 “快速定位慢 SQL” 的章节,检查是否存在全表扫描的大查询
- 检查 gRPC poll CPU 是否不足
3. Raft apply 线程短时间需要处理大量 raft 日志,apply log 过程速度慢
Apply 日志不及时可能导致 apply channel 中内存堆积,堆积严重导致系统内存不足则会出现 oom。通常是 apply wait duration 和 apply log duration 过高。相关监控位于:
- [tikv-detail]->[Raft IO]->[apply log duration]
- [tikv-detail]->[Raft propose]->[apply wait duration]
- [tikv-detail]->[Thread CPU]->[async apply CPU]
处理建议:
- 检查 apply cpu 线程是否存在瓶颈,如果 [Async apply CPU] 超过了 [apply-pool-size 数量] * 70% 说明需要加大 apply-pool-size。
- 检查 io 负载情况如磁盘吞吐量是否打满、写延迟是否过高。