tidb-in-action
8.3.1 TiDB 增加索引原理
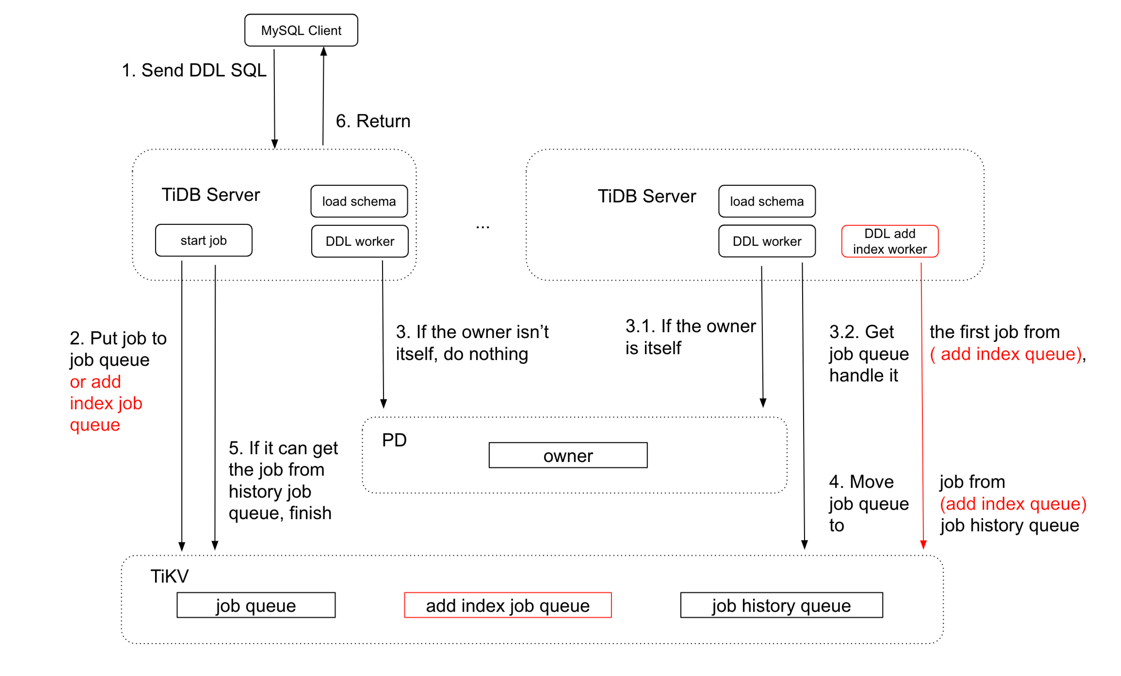
在普通关系型数据库中增加索引通常会有时间过长、锁表等风险,特别是在一张频繁更新数据的表上增加索引的时候,风险变得很大且不可控。 TiDB 的 DDL 通过实现 Google F1 的在线异步 schema 变更算法,来完成在分布式场景下的无锁,在线 schema 变更。从 TiDB 2.1 开始实现了并行 DDL ,新增了增加索引队列 (add index job queue) 以及增加索引线程 (add index worker) 用以加速增加索引的执行速度。
增加索引流程:
增加索引核心操作:
- 将索引的元信息添加到系统表中。
- 批量从读原始表中读数据并构建索引。
增加索引主要流程:
- 客户端发送添加索引请求到 TiDB ,TiDB 会检查表、索引等是否符合规范。
- 将添加索引请求转化成 Job 发送到添加索引的队列中 (add index job queue)。
- TiDB 会启动 Worker ,将 Job 从添加索引的队列中取出,并且写入到对应表信息中。
- 这时候 Worker 从 PD 中获取需要添加表的所有 region 范围,并且默认分成 256 个子 Job ,并发的去扫 region 中的所有数据,生成索引信息。
- 当所有子 Job 都完成之后,会将该 Job 放入历史队列中 (history ddl job)。