tidb-in-action
8.2.2 海量 Region 集群调优
在 TiDB 的架构中,所有数据以一定 range 将数据 key 切分成若干 Region 分布在多个 TiKV 实例上。随着数据的写入,一个集群中会产生上百万个甚至千万个 Region。单个 TiKV 实例上产生过多的 Region 会给集群带来较大的负担,影响整个集群的性能表现。
本将介绍 TiKV 核心模块 Raftstore 的工作流程,海量 Region 导致性能问题的原因,以及优化性能的方法。
1. Raftstore 的工作流程
一个 TiKV 实例上有多个 Region。Region 消息是通过 Raftstore 模块驱动 Raft 状态机来处理的。这些消息包括 Region 上读写请求的处理、Raft log 的持久化和复制、Raft 的心跳处理等。但是,Region 数量增多会影响整个集群的性能。为了解释这一点,需要先了解 TiKV 的核心模块 Raftstore 的工作流程。
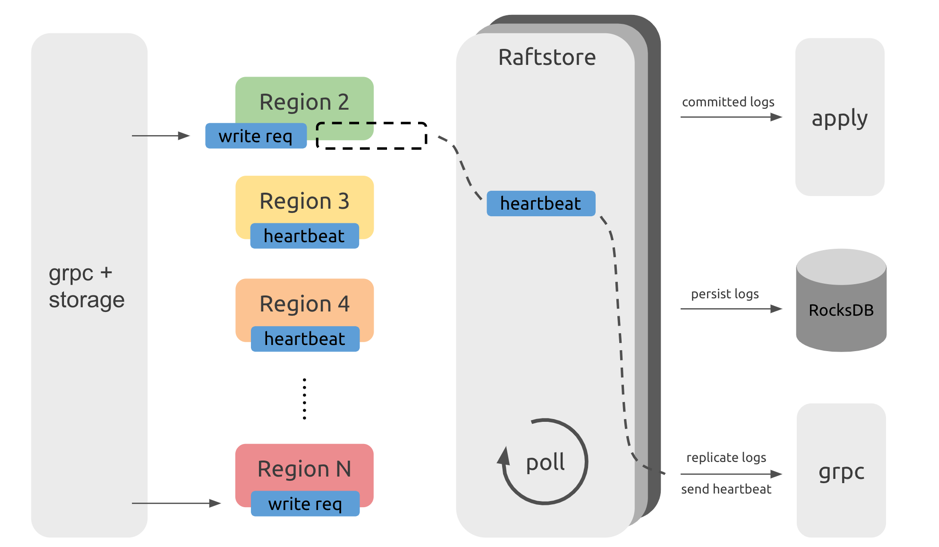
注意: 该图仅为示意,不代表代码层面的实际结构。
上图是 Raftstore 处理流程的示意图。如图所示,从 TiDB 发来的请求会通过 gRPC 和 storage 模块变成最终的 KV 读写消息,并被发往相应的 Region,而这些消息并不会被立即处理而是被暂存下来。Raftstore 会轮询检查每个 Region 是否有需要处理的消息。如果 Region 有需要处理的消息,那么 Raftstore 会驱动 Raft 状态机去处理这些消息,并根据这些消息所产生的状态变更去进行后续操作。例如,在有写请求时,Raft 状态机需要将日志落盘并且将日志发送给其他 Region 副本;在达到心跳间隔时,Raft 状态机需要将心跳信息发送给其他 Region 副本。
2. 性能问题
从 Raftstore 处理流程示意图可以看出,需要依次处理各个 Region 的消息。那么在 Region 数量较多的情况下,Raftstore 需要花费一些时间去处理大量 Region 的心跳,从而带来一些延迟,导致某些读写请求得不到及时处理。如果读写压力较大,Raftstore 线程的 CPU 使用率容易达到瓶颈,导致延迟进一步增加,进而影响性能表现。
通常在有负载的情况下,如果 Raftstore 的 CPU 使用率达到了 85% 以上,即可视为达到繁忙状态且成为了瓶颈,同时 Grafana TiKV 监控 Raft Propose 面板 propose wait duration 可能会高达百毫秒级别。
注意: Raftstore 的 CPU 使用率是指单线程的情况。如果是多线程 Raftstore,可等比例放大使用率。 由于 Raftstore 线程中有 I/O 操作,所以 CPU 使用率不可能达到 100%。
性能监控
可在 Grafana 的 TiKV 面板下查看相关的监控 metrics:
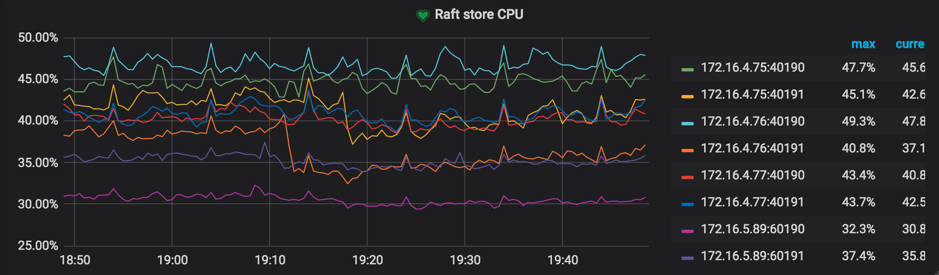
Thread-CPU 下的 Raft store CPU
参考值:低于 raftstore.store-pool-size * 85%。
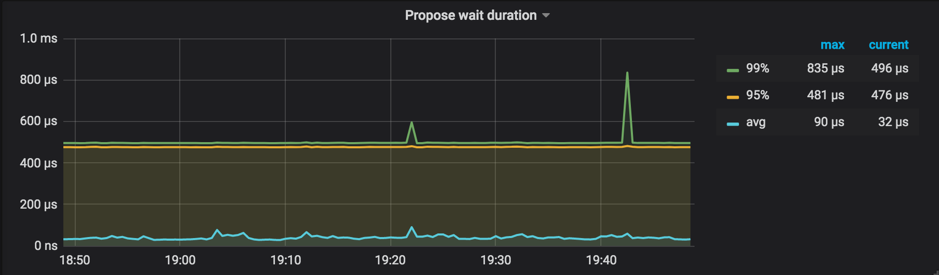
Raft Propose 下的 Propose wait duration
Propose wait duration 是从发送请求给 Raftstore,到 Raftstore 真正开始处理请求之间的延迟时间。如果该延迟时间较长,说明 Raftstore 比较繁忙或者处理 append log 比较耗时导致 Raftstore 不能及时处理请求。
参考值:低于 50-100ms。
3. 性能优化方法
找到性能问题的根源后,可从以下两个方向来解决性能问题:
- 减少单个 TiKV 实例的 Region 数
- 减少单个 Region 的消息数
方法一:增加 TiKV 实例
如果 I/O 资源和 CPU 资源都比较充足,可在单台机器上部署多个 TiKV 实例,以减少单个 TiKV 实例上的 Region 个数;或者增加 TiKV 集群的机器数。
方法二:调整 raft-base-tick-interval
除了减少 Region 个数外,还可以通过减少 Region 单位时间内的消息数量来减小 Raftstore 的压力。例如,在 TiKV 配置中适当调大 raft-base-tick-interval:
[raftstore]
raft-base-tick-interval = "2s"
raft-base-tick-interval 是 Raftstore 驱动每个 Region 的 Raft 状态机的时间间隔,也就是每隔该时长就需要向 Raft 状态机发送一个 tick 消息。增加该时间间隔,可以有效减少 Raftstore 的消息数量。 需要注意的是,该 tick 消息的间隔也决定了 election timeout 和 heartbeat 的间隔。示例如下:
raft-election-timeout = raft-base-tick-interval * raft-election-timeout-ticks
raft-heartbeat-interval = raft-base-tick-interval * raft-heartbeat-ticks
如果 Region Follower 在 raft-election-timeout 间隔内未收到来自 Leader 的心跳,就会判断 Leader 出现故障而发起新的选举。raft-heartbeat-interval 是 Leader 向 Follower 发送心跳的间隔,因此调大 raft-base-tick-interval 可以减少单位时间内 Raft 发送的网络消息,但也会让 Raft 检测到 Leader 故障的时间更长。
方法三:提高 Raftstore 并发数
TiKV 默认将 raftstore.store-pool-size 配置为 2。如果 Raftstore 出现瓶颈,可以根据实际情况适当调高该参数值,但不建议设置过高以免引入不必要的线程切换开销。
方法四:开启 Hibernate Region 功能
在实际情况中,读写请求并不会均匀分布到每个 Region 上,而是集中在少数的 Region 上。那么可以尽量减少暂时空闲的 Region 的消息数量,这也就是 Hibernate Region 的功能。无必要时可不进行 raft-base-tick,即不驱动空闲 Region 的 Raft 状态机,那么就不会触发这些 Region 的 Raft 产生心跳信息,极大地减小了 Raftstore 的工作负担。
截至 TiDB v4.0,Hibernate Region 仍是一个实验功能,在 TiKV master 分支上已经默认开启。可根据实际情况和需求来开启该功能。Hibernate Region 的配置说明请参考配置 Hibernate Region。
方法五:开启 Region Merge
注意: Region Merge 在 TiDB v4.0 中默认开启。
开启 Region Merge 也能减少 Region 的个数。与 Region Split 相反,Region Merge 是通过调度把相邻的小 Region 合并的过程。在集群中删除数据或者执行 Drop Table/Truncate Table 语句后,可以将小 Region 甚至空 Region 进行合并以减少资源的消耗。
通过 pd-ctl 设置以下参数即可开启 Region Merge 以及调整 Region Merge 速度:
>> pd-ctl config set max-merge-region-size 20
>> pd-ctl config set max-merge-region-keys 200000
>> pd-ctl config set merge-schedule-limit 8
详情请参考如何配置 Region Merge 和 PD 配置文件描述。 同时,默认配置的 Region Merge 的参数设置较为保守,可以根据需求参考 PD 调度策略最佳实践 中提供的方法加快 Region Merge 过程的速度。