tidb-in-action
8.2.1 TiKV 线程池优化
在 TiKV 4.0 中,线程池主要由 gRPC、Scheduler、UnifyReadPool、Store、Apply、RocksDB 以及其它一些占用 CPU 不多的定时任务与检测组件组成。
● gRPC 线程池是 TiKV 所有读写请求的总入口,它会把不同任务类型的请求转发给不同的线程池。
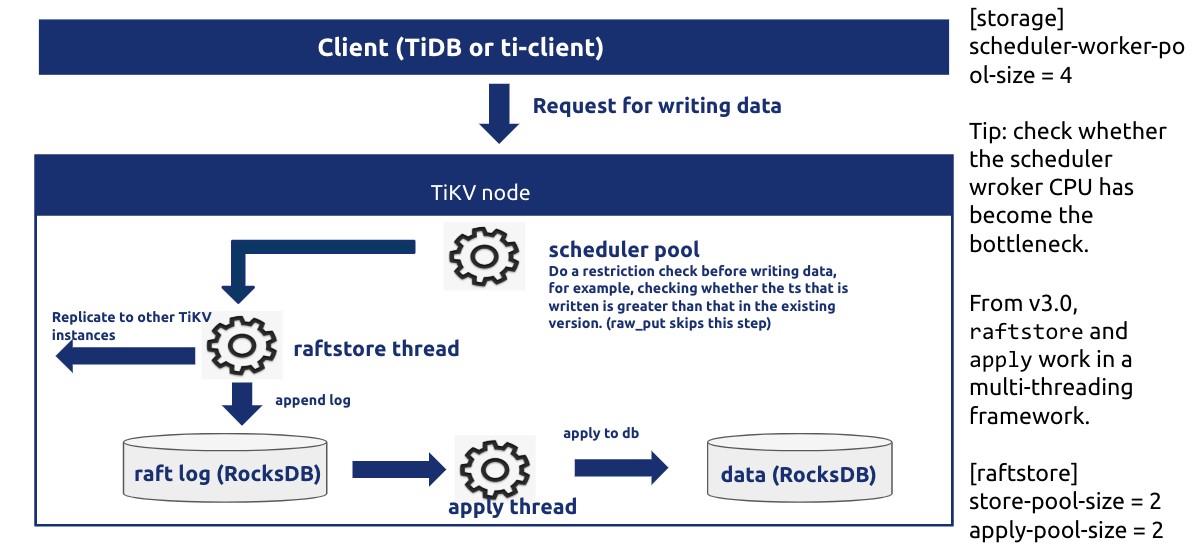
● Scheduler 线程池负责检测写事务冲突,把事务的两阶段提交、悲观锁上锁、事务回滚等请求转化为 key-value 对数组,然后交给 Store 线程进行 Raft 日志复制。
● Raftstore 线程池负责处理所有的 Raft 消息以及添加新日志的提议(Propose)、将日志写入到磁盘,当日志在 Raft Group 中达成多数一致(即 Raft 论文中描述的 Commit Index)后,它就会把该日志发送给 Apply 线程。
● Apply 线程收到从 Store 线程池发来的已提交日志后将其解析为 key-value 请求,然后写入 RocksDB 并且调用回调函数通知 gRPC 线程池中的写请求完成,返回结果给客户端。
● RocksDB 线程池是 RocksDB 进行 Compact 和 Flush 任务的线程池,关于 RocksDB 的架构与 Compact 操作请参考 RocksDB: A Persistent Key-Value Store for Flash and RAM Storage
● UnifyReadPool 是 TiKV 4.0 推出的新特性,它由之前的 Coprocessor 线程池与 Storage Read Pool 合并而来,所有的读取请求包括 kv get、kv batch get、raw kv get、coprocessor 等都会在这个线程池中执行。
1. GRPC
gRPC 线程池的大小默认配置(server.grpc-concurrency)是 4。由于 gRPC 线程池几乎不会有多少计算开销,它主要负责网络 IO、反序列化请求,因此该配置通常不需要调整,如果部署的机器 CPU 特别少(小于等于 8),可以考虑将该配置(server.grpc-concurrency)设置为 2,如果机器配置很高,并且 TiKV 承担了非常大量的读写请求,观察到 Grafana 上的监控 Thread CPU 的 gRPC poll CPU 的数值超过了 server.grpc-concurrency 大小的 80%,那么可以考虑适当调大 server.grpc-concurrency 以控制该线程池使用率在 80% 以下。
2. Scheduler
Scheduler 线程池的大小配置 (storage.scheduler-worker-pool-size) 在 TiKV 检测到机器 CPU 数大于等于 16 时默认为 8,小于 16 时默认为 4。它主要用于将复杂的事务请求转化为简单的 key-value 读写。但是 scheduler 线程池本身不进行任何写操作,如果检测到有事务冲突,那么它会提前返回冲突结果给客户端,否则的话它会把需要写入的 key-value 合并成一条 Raft 日志交给 raftstore 线程进行 raft 日志复制。通常来说为了避免过多的线程切换,最好确保 scheduler 线程池的利用率保持在 50%~75% 之间。(如果线程池大小为 8 的话,那么 Grafana 上的 Thread CPU 的 scheduler worker CPU 应当在 400%~600% 之间较为合理)
3. Raftstore
Raftstore 线程池是 TiKV 最为复杂的一个线程池,默认大小(raftstore.store-pool-size)为 2,所有的写请求都会先在 store 线程 fsync 的方式写入 RocksDB (除非手动将 raftstore.sync-log 设置为 true;而 raftstore.sync-log 设置为 false,可以提升一部分写性能,但也会造成数据丢失的可能)。由于存在 IO,store 线程理论上不可能达到 100% 的 CPU。为了尽可能地减少写磁盘次数,将多个写请求攒在一起写入 RocksDB,最好控制其 CPU 使用在 40% ~ 60%。千万不要为了提升写性能盲目增大 store 线程池大小,这样可能反而会适得其反,增加了磁盘负担让性能变差。
● 监控 Raft IO 中的 append log duration 表示 Store 线程处理一批 Raft Message 并且将需要持久化的日志写入 RocksDB (这里存储的格式是 Raft 日志格式)中的时间。如果该指标较高(P99 大于 500ms),说明盘比较慢(查看监控 Node Exporter 中的 disk latency 判断盘的性能是否有问题),或者是写入 RocksDB 时触发了 Write Stall 。此时可以查看 RocksDB-raft 中的 write stall duration,该指标正常情况下应该为 0, 若不为 0 则可能发送了 write stall。
4. UnifyReadPool
UnifyReadPool 负责处理所有的读取请求。默认配置(readpool.unified.max-thread-count)大小为机器 CPU 数的 80%。通常建议根据业务负载特性调整其 CPU 使用率在 60%~90% 之间。
5. RocksDB
RocksDB 线程池是 RocksDB 进行 Compact 和 Flush 任务的线程池,通常不需要配置,如果机器 CPU 数较少,可将 rocksdb.max-background-jobs 与 raftdb.max-background-jobs 同时改为 4. 如果遇到了 Write Stall ,查看 Grafana 监控上 RocksDB-kv 中的 Write Stall Reason 有哪些指标不为 0。如果是由 pending compaction bytes 相关原因引起的,可将 rocksdb.max-sub-compactions 设置为 2 (该配置表示单次 compaction job 允许使用的子线程数量)。如果原因是 memtable count 相关,建议调大所有列的 max-write-buffer-number (默认为 5)。如果原因是 level0 file limit 相关,建议调大如下参数:
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger